深入理解Linux網絡之內核是如何發送網絡包的
現在的服務器上的網卡一般都是支持多隊列的。每一個隊列都是由一個RingBuffer表示的,開啟了多隊列以后的網卡就會有多個RingBuffer。
網卡啟動時最重要的任務就是分配和初始化RingBuffer,在網卡啟動的時候會調用到__igb_open函數,RingBuffer就是在這里分配的。
static int __igb_open(struct net_device *netdev, bool resuming){ // 分配傳輸描述符數組 err = igb_setup_all_tx_resources(adpater); // 分配接收描述符數組 err = igb_setup_all_rx_resources(adpater); // 注冊中斷處理函數 err = igb_request_irq(adapter); if(err)goto err_req_irq; // 啟用NAPI for(i = 0; i < adapter->num_q_vectors; i++)napi_enable(&(adapter->q_vector[i]->napi)); ......}static int igb_setup_all_tx_resources(struct igb_adapter *adapter){ // 有幾個隊列就構造幾個RingBuffer for(int i = 0; i < adapter->num_tx_queues; i++) { igb_setup_tx_resources(adapter->tx_ring[i]); }}igb_setup_tx_resources內部也是申請了兩個數組,igb_tx_buffer數組和e1000_adv_tx_desc數組,一個供內核使用,一個供網卡硬件使用。
在這個時候它們之間還沒什么關系,將來在發送數據的時候這兩個數組的指針都指向同一個skb,這樣內核和硬件就能共同訪問同樣的數據了。
內核往skb寫數據,網卡硬件負責發送。
硬中斷的處理函數igb_msix_ring也是在__igb_open函數中注冊的。
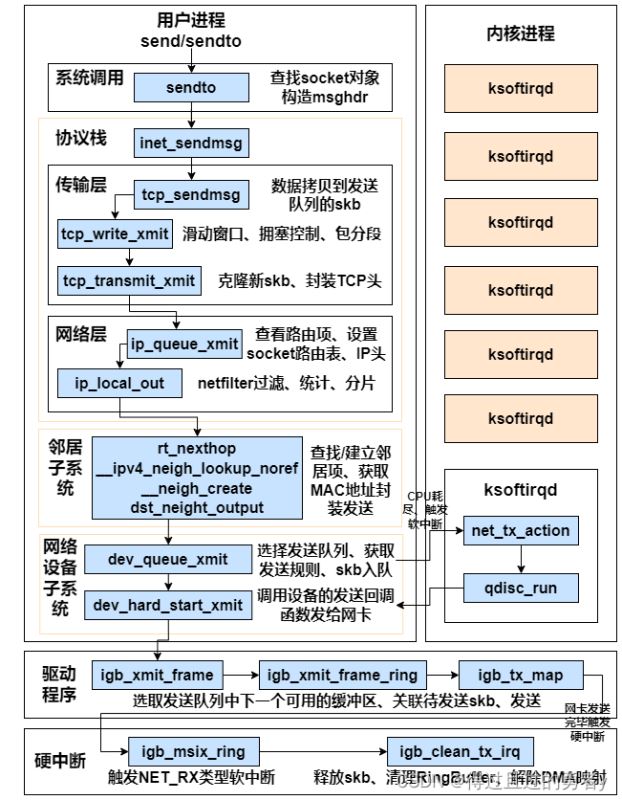
四、數據從用戶進程到網卡的詳細過程1)系統調用實現send系統調用內部真正使用的是sendto系統調用,主要做了兩件事:
在內核中把真正的socket找出來構造struct msghdr對象, 把用戶傳入的數據,比如buffer地址(用戶待發送數據的指針)、數據長度、發送標志都裝進去SYS_CALL_DEFINE6(sendto, ......){ sock = sockfd_lookup_light(fd, &err, &fput_needed); struct msghdr msg; struct iovec iov; iov.iov_base = buff; iov.iov_len = len; msg.msg_iovlen = &iov; msg.msg_iov = &iov; msg.msg_flags = flags; ...... sock_sendmsg(sock, &msg, len);}sock_sendmsg經過一系列調用,最終來到__sock_sendmsg_nosec中調用sock->ops->sendmsg
對于AF_INET協議族的socket,sendmsg的實現統一為inet_sendmsg
2)傳輸層處理1. 傳輸層拷貝
在進入協議棧inet_sendmsg以后,內核接著會找到sock中具體的協議處理函數,對于TCP協議而言,sk_prot操作函數集實例為tcp_prot,其中.sendmsg的實現為tcp_sendmsg(對于UDP而言中的為udp_sendmsg)。
int inet_sendmsg(......){ ...... return sk->sk_prot->sendmsg(iocb, sk, msg, size);}int tcp_sendmsg(......){ ...... // 獲取用戶傳遞過來的數據和標志 iov = msg->msg_iov; // 用戶數據地址 iovlen = msg->msg_iovlen; // 數據塊數為1 flags = msg->msg_flags; // 各種標志 copied = 0; // 已拷貝到發送隊列的字節數 // 遍歷用戶層的數據塊 while(--iovlen >= 0) {// 待發送數據塊的長度size_t seglen = iov->len; // 待發送數據塊的地址unsigned char __user *from = iov->iov_base;// 指向下一個數據塊iovlen++; ...... while(seglen > 0) { int copy = 0; int max = size_goal; // 單個skb最大的數據長度 skb = tcp_write_queue_tail(sk); // 獲取發送隊列最后一個skb // 用于返回發送隊列第一個數據包,如果不是NULL說明還有未發送的數據 if(tcp_send_head(sk)) { ...copy = max - skb->len; // 該skb還可以存放的字節數 } // 需要申請新的skb if(copy <= 0) {// 發送隊列的總大小大于等于發送緩存的上限,或尚發送緩存中未發送的數據量超過了用戶的設置值,進入等待if(!sk_stream_memory_free(sk)) { goto wait_for_sndbuf;}// 申請一個skbskb = sk_stream_alloc_skb(sk, select_size(sk, sg), sk->sk_allocation);...// 把skb添加到sock的發送隊列尾部skb_entail(sk, skb); } if(copy > seglen)copy = seglen; // skb的線性數據區中有足夠的空間 if(skb_availroom(skb)) > 0) {copy = min_t(int, copy, skb_availroom(skb));// 將用戶空間的數據拷貝到內核空間,同時計算校驗和err = skb_add_data_nocache(sk, skb, from, copy);if(err) goto do_fault; } // 線性數據區用完,使用分頁區 else{... }這個函數的實現邏輯比較復雜,代碼總只顯示了skb拷貝的相關部分,總體邏輯如下:
如果使用了TCP Fast Open,則會在發送SYN包的同時帶上數據
如果連接尚未建好,不處于ESTABLISHED或者CLOSE_WAIT狀態則進程進入睡眠,等待三次握手的完成
獲取當前的MSS(最大報文長度)和size_goal(一個理想的TCP數據包大小,受MTU、MSS、TCP窗口大小影響)
如果網卡支持GSO(利用網卡分片),size_goal會是MSS的整數倍遍歷用戶層的數據塊數組
獲取發送隊列的最后一個skb,如果是尚未發送的,且長度未到達size_goal,那么向這個skb繼續追加數據
否則申請一個新的skb來裝載數據
如果發送隊列的總大小大于等于發送緩存的上限,或者發送緩存中尚未發送的數據量超過了用戶的設置值:設置發送時發送緩存不夠的標志,進入等待申請一個skb,其線性區的大小為通過select_size()得到的線性數據區中TCP負荷的大小和最大的協議頭長度,申請失敗則等待可用內存前兩步成功則更新skb的TCP控制塊字段,把skb加入發送隊列隊尾,增加發送隊列的大小,減少預分配緩存的大小將數據拷貝至skb中
如果skb的線性數據區還有剩余,就復制到線性數據區同時計算校驗和
如果已經用完則使用分頁區
檢查分頁區是否有可用空間,沒有則申請新的page,申請失敗則說明內存不足,之后會設置TCP內存壓力標志,減小發送緩沖區的上限,睡眠等待內存判斷能否往最后一個分頁追加數據,不能追加時,檢查分頁數是否已經達到了上限或網卡是否不支持分散聚合,如果是的話就將skb設置為PSH標志,然后回到4.2中重新申請一個skb來繼續填裝數據從系統層面判斷此次分頁發送緩存的申請是否合法拷貝用戶空間的數據到skb的分頁中,同時計算校驗和。更新skb的長度字段,更新sock的發送隊列大小和預分配緩存如果把數據追加到最后一個分頁了,更新最后一個分頁的數據大小。否則初始化新的分頁拷貝成功后更新:發送隊列的最后一個序號、skb的結束序號、已經拷貝到發送隊列的數據量
發送數據
如果所有數據都拷貝好了就退出循環進行發送如果skb還可以繼續裝填數據或者發送的是帶外數據那么就繼續拷貝數據先不發送如果為發送的數據已經超過最大窗口的一半則設置PUSH標志后盡可能地將發送隊列中的skb發送出去如果當前skb就是發送隊列中唯一一個skb,則將這一個skb發送出去如果上述過程中出現緩存不足,且已經有數據拷貝到發送隊列了也直接發送這里的發送數據只是指調用tcp_push或者tcp_push_one(情況4)或者__tcp_push_pending_frames(情況3)嘗試發送,并不一定真的發送到網絡(tcp_sendmsg主要任務只是將應用程序的數據封裝成網絡數據包放到發送隊列)。
數據何時實際被發送到網絡,取決于許多因素,包括但不限于:
TCP的擁塞控制算法:TCP使用了復雜的擁塞控制算法來防止網絡過載。如果TCP判斷網絡可能出現擁塞,它可能會延遲發送數據。發送窗口的大小:TCP使用發送窗口和接收窗口來控制數據的發送和接收。如果發送窗口已滿(即已發送但未被確認的數據量達到了發送窗口的大小),那么TCP必須等待接收到確認信息后才能發送更多的數據。網絡設備(如網卡)的狀態:如果網絡設備繁忙或出現錯誤,數據可能會被暫時掛起而無法立即發送。struct sk_buff(常簡稱為skb)在Linux網絡棧中表示一個網絡包。它有兩個主要的數據區用來存儲數據,分別是線性數據區(linear data area)和分頁區(paged data area)。
線性數據區(linear data area): 這個區域連續存儲數據,并且能夠容納一個完整的網絡包的所有協議頭,比如MAC頭、IP頭和TCP/UDP頭等。除了協議頭部,線性數據區還可以包含一部分或全部的數據負載。每個skb都有一個線性數據區。分頁區(paged data area): 一些情況下,為了優化內存使用和提高性能,skb的數據負載部分可以存儲在一個或多個內存頁中,而非線性數據區。分頁區的數據通常只包含數據負載部分,不包含協議頭部。如果一個skb的數據全部放入了線性數據區,那么這個skb就沒有分頁區。這種設計的好處是,對于大的數據包,可以將其數據負載部分存儲在分頁區,避免對大塊連續內存的分配,從而提高內存使用效率,減少內存碎片。另外,這種設計也可以更好地支持零拷貝技術。例如,當網絡棧接收到一個大數據包時,可以直接將數據包的數據負載部分留在原始的接收緩沖區(即分頁區),而無需將其拷貝到線性數據區,從而節省了內存拷貝的開銷。
2. 傳輸層發送
上面的發送數據步驟,不論是調用__tcp_push_pending_frames還是tcp_push_one,最終都會執行到tcp_write_xmit(在網絡協議中學到滑動窗口、擁塞控制就是在這個函數中完成的),函數的主要邏輯如下:
如果要發送多個數據段則先發送一個路徑mtu探測檢測擁塞窗口的大小,如果窗口已滿(通過窗口大小-正在網絡上傳輸的包數目判斷)則不發送檢測當前報文是否完全在發送窗口內,如果不是則不發送判斷是否需要延時發送(取決于擁塞窗口和發送窗口)根據需要對數據包進行分段(取決于擁塞窗口和發送窗口)tcp_transmit_skb發送數據包如果push_one則結束循環,否則繼續遍歷隊列發送結束循環后如果本次有數據發送,則對TCP擁塞窗口進行檢查確認這里我們只關注發送的主過程,其他部分不過多展開,即來到tcp_transmit_skb函數
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it, gfp_t gfp_mask){ // 1.克隆新的skb出來 if(likely(clone_it)) { skb = skb_clone(skb, gfp_mask);...... } // 2.封裝TCP頭 th = tcp_hdr(skb); th->source = inet->inet_sport; th->dest = inet->inet_dport; th->window = ...; th->urg = ...; ...... // 3.調用網絡層發送接口 err = icsk->icsk_af_ops->xmit(skb, &inet->cort.fl);}第一件事就是先克隆一個新的skb,因為skb后續在調用網絡層,最后到達網卡發送完成的時候,這個skb會被釋放掉。而TCP協議是支持丟失重傳的,在收到對方的ACK之前,這個skb不能被刪除掉。所以內核的做法就是每次調用網卡發送的時候,實際上傳遞出去的是skb的一個拷貝。等收到ACK再真正刪除。
第二件事是修改skb的TCP頭,根據實際情況把TCP頭設置好。實際上skb內部包含了網絡協議中所有的頭,在設置TCP頭的時候,只是把指針指向skb合適的位置。后面設置IP頭的時候,再把指針挪動一下即可,避免了頻繁的內存申請和拷貝,提高效率。
tcp_transmit_skb是發送數據位于傳輸層的最后一步,調用了網絡層提供的發送接口icsk->icsk_Af_ops->queue_xmit()之后就可以進入網絡層進行下一層的操作了。
3)網絡層發送處理在tcp_ipv4中,queue_xmit指向的是ip_queue_xmit,具體實現如下:
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl){ // 檢查socket中是否有緩存的路由表 rt = (struct rtable*)__sk_dst_check(sk, 0); ...... if(rt == null) { // 沒有緩存則展開查找路由項并緩存到socket中rt = ip_route_output_ports(...); sk_setup_caps(sk, &rt->dst); } // 為skb設置路由表 skb_dst_set_noref(skb, &rt->dst); // 設置IP頭 iph = ip_hdr(skb); ip->protocol = sk->sk_protocol; iph->ttl = ip_select_ttl(inet, &rt->dst); ip->frag_off = ...; ip_copy_addr(iph, f14); ...... // 發送 ip_local_out(skb);}這個函數主要做的就是找到該把這個包發往哪,并構造好IP包頭。它會去查詢socket中是否有緩存的路由表,如果有則直接構造包頭,如果沒有就去查詢并緩存到sokect,然后為skb設置路由表,最后封裝ip頭,發往ip_local_out函數。
ip_local_out中主要會經過__ip_local_out => nf_hook 的過程進行netfilter的過濾。如果使用iptables配置了一些規則,那么這里將檢測到是否命中規則,然后進行相應的操作,如網絡地址轉換、數據包內容修改、數據包過濾等。如果設置了非常復雜的netfilter規則,則在這個函數會導致進程CPU的開銷大增。經過netfilter處理之后,(忽略其他部分)調用dst_output(skb)函數。
dst_output會去調用skb_dst(skb)->output(skb),即找到skb的路由表(dst條目),然后調用路由表的output方法。這里是個函數指針,指向的是ip_output方法。
在ip_output方法中首先會進行一些簡單的統計工作,隨后再次執行netfilter過濾。過濾通過之后回調ip_finish_output。
在ip_finish_output中,會校驗數據包的長度,如果大于MTU,就會執行分片。MTU的大小是通過MTU發現機制確定,在以太網中為1500字節。分片會帶來兩個問題:
需要進行額外的處理,會有性能開銷只要一個分片丟失,整個包都要重傳如果不需要分片則調用ip_finish_output2函數,根據下一跳的IP地址查找鄰居項,找不到就創建一個,然后發給下一層——鄰居子系統。
總體過程如下:
ip_queue_xmit
查找并設置路由項設置IP頭ip_local_out:netfilter過濾
ip_output
統計工作再次netfilter過濾ip_finish_output
大于MTU的話進行分片調用ip_finish_output24)鄰居子系統鄰居子系統是位于網絡層和數據鏈路層中間的一個系統,其作用是為網絡層提供一個下層的封裝,讓網絡層不用關心下層的地址信息,讓下層來決定發送到哪個MAC地址。
鄰居子系統不位于協議棧net/ipv4/目錄內,而是位于net/core/neighbour.c,因為無論對于ipv4還是ipv6都需要使用該模塊
在鄰居子系統中主要查找或者創建鄰居項,在創建鄰居項時有可能會發出實際的arp請求。然后封裝MAC頭,將發生過程再傳遞給更下層的網絡設備子系統。
ip_finish_output2的實現邏輯大致流程如下:
rt_nexthop:獲取路由下一跳的IP信息
__ipv4_neigh_lookup_noref:根據下一條IP信息在arp緩存中查找鄰居項
__neigh_create:創建一個鄰居項,并加入鄰居哈希表
dst_neight_output => neighbour->output(實際指向neigh_resolve_output):
封裝MAC頭(可能會先觸發arp請求)調用dev_queue_xmit發送到下層5)網絡設備子系統鄰居子系統通過dev_queue_xmit進入網絡設備子系統,dev_queue_xmit的工作邏輯如下
選擇發送隊列獲取排隊規則存在隊列則調用__dev_xmit_skb繼續處理在前面講過,網卡是有多個發送隊列的,所以首先需要選擇一個隊列進行發送。隊列的選擇首先是通過獲取用戶的XPS配置(為隊列綁核),如果沒有配置則調用skb_tx_hash去計算出選擇的隊列。接著會根據與此隊列關聯的qdisc得到該隊列的排隊規則。
最后會根據是否存在隊列(如果是發給回環設備或者隧道設備則沒有隊列)來決定后續數據包流向。對于存在隊列的設備會進入__dev_xmit_skb函數。
在Linux網絡子系統中,qdisc(Queueing Discipline,隊列規則)是一個用于管理網絡包排隊和發送的核心組件。它決定了網絡包在發送隊列中的排列順序,以及何時從隊列中取出包進行發送。qdisc還可以應用于網絡流量控制,包括流量整形(traffic shaping)、流量調度(traffic scheduling)、流量多工(traffic multiplexing)等。
Linux提供了許多預定義的qdisc類型,包括:
pfifo_fast:這是默認的qdisc類型,提供了基本的先入先出(FIFO)隊列行為。mq:多隊列時的默認類型,本身并不進行任何數據包的排隊或調度,而是為網絡設備的每個發送隊列創建和管理一個子 qdisc。tbf (Token Bucket Filter):提供了基本的流量整形功能,可以限制網絡流量的速率。htb (Hierarchical Token Bucket):一個更復雜的流量整形qdisc,可以支持多級隊列和不同的流量類別。sfq (Stochastic Fairness Queueing):提供了公平隊列調度,可以防止某一流量占用過多的帶寬。每個網絡設備(如eth0、eth1等)都有一個關聯的qdisc,用于管理這個設備的發送隊列。用戶可以通過tc(traffic control)工具來配置和管理qdisc。
對于支持多隊列的網卡,Linux內核為發送和接收隊列分別分配一個qdisc。每個qdisc獨立管理其對應的隊列,包括決定隊列中的數據包發送順序,應用流量控制策略等。這樣,可以實現每個隊列的獨立調度和流量控制,提高整體網絡性能。
我們可以說,對于支持多隊列的網卡,內核中的每個發送隊列都對應一個硬件的發送隊列(也就是 Ring Buffer)。選擇哪個內核發送隊列發送數據包,也就決定了數據包將被放入哪個 Ring Buffer。數據包從 qdisc 的發送隊列出隊后,會被放入 Ring Buffer,然后由硬件發送到網絡線路上。所以,Ring Buffer 在發送路徑上位于發送隊列之后。
將struct sock的發送隊列和網卡的Ring Buffer之間設置一個由qdisc(隊列規則)管理的發送隊列,可以提供更靈活的網絡流量控制和調度策略,以適應不同的網絡環境和需求。
下面是一些具體的原因:
流量整形和控制:qdisc可以實現各種復雜的排隊規則,用于控制數據包的發送順序和時間。這可以用于實現流量整形(比如限制數據的發送速率以避免網絡擁塞)和流量調度(比如按照優先級或服務質量(QoS)要求來調度不同的數據包)。對抗網絡擁塞:qdisc可以通過管理發送隊列,使得在網絡擁塞時可以控制數據的發送,而不是簡單地將所有數據立即發送出去,這可以避免網絡擁塞的加劇。公平性:在多個網絡連接共享同一個網絡設備的情況下,qdisc可以確保每個連接得到公平的網絡帶寬,而不會因為某個連接的數據過多而餓死其他的連接。性能優化:qdisc可以根據網絡設備的特性(例如,對于支持多隊列(Multi-Queue)的網卡)和當前的網絡條件來優化數據包的發送,以提高網絡的吞吐量和性能。__dev_xmit_skb分為三種情況:
qdisc停用:釋放數據并返回代碼設置為NET_XMIT_DROP
qdisc允許繞過排隊系統&&沒有其他包要發送&&qdisc沒有運行:繞過排隊系統,調用sch_direct_xmit發送數據
其他情況:正常排隊
調用q->enqueue入隊調用__qdisc_run開始發送void __qdisc_run(struct Qdisc *q){ int quota = weight_p; // 循環從隊列取出一個skb并發送 while(qdisc_restart(q)) {// 如果quota耗盡或其他進程需要CPU則延后處理if(--quota <= 0 || need_resched) { // 將觸發一次NET_TX_SOFTIRQ類型的softirq __netif_shcedule(q); break;} }}從上述代碼中可以看到,while循環不斷地從隊列中取出skb并進行發送,這個時候其實占用的都是用戶進程系統態時間sy,只有當quota用盡或者其他進程需要CPU的時候才觸發軟中斷進行發送。
這就是為什么服務器上查看/proc/softirqs,一般NET_RX要比NET_TX大得多的原因。對于接收來說,都要經過NET_RX軟中斷,而對于發送來說,只有系統配額用盡才讓軟中斷上。
這里我們聚焦于qdisc_restart函數上,這個函數用于從qdisc隊列中取包并發給網絡驅動
static inline int qdisc_restart(struct Qdisc *q){ struct sk_buff *skb = dequeue_skb(q); if (!skb)return 0; ...... return sch_direct_xmit(skb, q, dev, txq, root_lock);}首先調用 dequeue_skb() 從 qdisc 中取出要發送的 skb。如果隊列為空,返回 0, 這將導致上層的 qdisc_restart() 返回 false,繼而退出 while 循環。
如果拿到了skb則調用sch_direct_xmit繼續發送,該函數會調用dev_hard_start_xmit,進入驅動程序發包,如果無法發送則重新入隊。
即整個__qdisc_run的整體邏輯為:while 循環調用 qdisc_restart(),后者取出一個 skb,然后嘗試通過 sch_direct_xmit() 來發送;sch_direct_xmit 調用 dev_hard_start_xmit 來向驅動程序進行實際發送。任何無法發送的 skb 都重新入隊,將在 NET_TX softirq 中進行發送。
6)軟中斷調度上一部分中如果發送網絡包的時候CPU耗盡了,會調用進入__netif_schedule,該函數會進入__netif_reschedule,將發送隊列設置到softnet_data上,并最終發出一個NET_TX_SOFTIRQ類型的軟中斷。軟中斷是由內核進程運行的,該進程會進入net_tx_action函數,在該函數中能獲得發送隊列,并最終也調用到驅動程序的入口函數dev_hard_start_xmit。
從觸發軟中斷開始以后發送數據消耗的CPU就都顯示在si中,而不會消耗用戶進程的系統時間
static void net_tx_action(struct softirq_action *h){ struct softnet_data *sd = &__get_cpu_var(softnet_data); // 如果softnet_data設置了發送隊列 if(sd->output_queue) { // 將head指向第一個qdisc head = sd->output_queue;// 遍歷所有發送隊列 while(head) { struct Qdisc *q = head; head = head->next_sched; // 處理數據 qdisc_run(q);} }}static inline void qdisc_run(struct Qdisc *q){ if(qdisc_run_begin(q)) __qdisc_run(q);}可以看到軟中斷的處理中,最后和前面一樣都是調用了__qdisc_run。也就是說不管是在qdisc_restart中直接處理,還是軟中斷來處理,最終實際都會來到dev_hard_start_xmit(__qdisc_run => qdisc_restart => dev_hard_start_xmit)。
7)igb網卡驅動發送通過前面的介紹可知,無論對于用戶進程的內核態,還是對于軟中斷上下文,都會調用網絡設備子系統的dev_hard_start_xmit函數,在這個函數中,會調用驅動里的發送函數igb_xmit_frame。在驅動函數里,會將skb掛到RingBuffer上,驅動調用完畢,數據包真正從網卡發送出去。
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, struct netdev_queue *txq){ // 獲取設備的回調函數ops const struct net_device_ops * ops = dev->netdev_ops; // 獲取設備支持的功能列表 features = netif_skb_features(skb); // 調用驅動的ops里的發送回調函數ndo_start_xmit將數據包傳給網卡設備 skb_len = skb->len; rc = ops->ndo_start_xmit(skb, dev);}這里ndo_start_xmit是網卡驅動要實現的函數,igb網卡驅動中的實現是igb_xmit_frame(在網卡驅動程序初始化的時候賦值的)。igb_xmit_frame主要會去調用igb_xmit_frame_ring函數
netdev_tx_t igb_xmit_frame_ring(struct sk_buff *skb, struct igb_ring *tx_ring){ // 獲取TX queue中下一個可用緩沖區的信息 first = &tx_ring->tx_buffer_info[tx_ring->next_to_use]; first->skb = skb; first->bytecount = skb->len; first->gso_segs = 1; // 準備給設備發送的數據 igb_tx_map(tx_ring, first, hdr_len);}static void igb_tx_map(struct igb_ring *tx_ring, struct igb_tx_buffer *first, const u8 hdr_len){ // 獲取下一個可用的描述符指針 tx_desc = IGB_TX_DESC(tx_ring, i); // 為skb->data構造內存映射,以允許設備通過DMA從RAM中讀取數據 dma = dma_map_single(tx_ring->dev, skb->data, size, DMA_TO_DEVICE); // 遍歷該數據包的所有分片,為skb的每個分片生成有效映射 for(frag = &skb_shinfo(skb)->frags[0]; ; flag++){tx_desc->read.buffer_addr = cpu_to_le64(dma); tx_desc->read.cmd_type_len = ...; tx_desc->read.olinfo_status = 0; } // 設置最后一個descriptor cmd_type |= size | IGB_TXD_DCMD; tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type);}在這里從網卡的發送隊列的RingBuffer上取下來一個元素,并將skb掛到元素上。然后使用igb_tx_map函數將skb數據映射到網卡可訪問的內存DMA區域。
這里可以理解為&tx_ring->tx_buffer_info[tx_ring->next_to_use]拿到了RingBuffer發送隊列中指針數組(前文提到的igb_tx_buffer,網卡啟動的時候創建的供內核使用的數組)的下一個可用的元素,然后為其填充skb、byte_count等數據。
填充完成之后,獲取描述符數組(前文提到的e1000_adv_tx_desc,網卡啟動的時候創建的供網卡使用的數組)的下一個可用元素。
調用dma_map_single函數創建內存和設備之間的DMA映射,tx_ring->dev是設備的硬件描述符,即網卡,skb->data是要映射的地址,size是映射的數據的大小,即數據包的大小,DMA_TO_DEVICE是指映射的方向,這里是數據將從內存傳輸到設備,返回的調用結果是一個DMA地址,存儲在dma變量中,設備可以直接通過這個地址訪問到skb的數據。
最后就是為前面拿到的描述符填充信息,將dma賦值給buffer_addr,網卡使用的時候就是從這里拿到數據包的地址。
當所有需要的描述符都建好,且skb的所有數據都映射到DMA地址后,驅動就會進入到它的最后一步,觸發真實的發送。
到目前為止我們可以這么理解:
應用程序將數據發送到 socket,這些數據會被放入與 sock 中的發送隊列。然后,網絡協議棧(例如 TCP 或 UDP)將這些數據從 socket 的發送隊列中取出,往下層封裝,然后將這些數據包放入由 qdisc 管理的設備發送隊列中。最后,這些數據包將從設備發送隊列出隊,放置到RingBuffer的指針數組中,通過dma將數據包的地址映射到可供網卡訪問的內存DMA區域,由硬件讀取后發送到網絡上。
五、RingBuffer內存回收當數據發送完以后,其實工作并沒有結束,因為內存還沒有清理。當發送完成的時候,網卡設備會觸發一個硬中斷(硬中斷會去觸發軟中斷)來釋放內存。
這里需要注意的就是,雖然是數據發送完成通知,但是硬中斷觸發的軟中斷是NET_RX_SOFTIRQ,這也就是為什么軟中斷統計中RX要高于TX的另一個原因。
硬中斷中會向softnet_data添加poll_list,軟中斷中輪詢后調用其poll回調函數,具體實現是igb_poll,其會在q_vector->tx.ring存在時去調用igb_clean_tx_irq。
static bool igb_clean_tx_irq(struct igb_q_vector *q_vector){ // 釋放skb dev_kfree_skb_any(tx_buffer->skb); // 清除tx_buffer數據 tx_buffer->skb = NULL; // 將tx_buffer指定的DMA緩沖區的長度設置為0 dma_unmap_len_set(tx_buffer, len 0); // 清除最后的DMA位置,解除映射 while(tx_desc != eop_desc) { }}其實邏輯無非就是清理了skb(其中data保存的數據包沒有釋放),解決了DMA映射等,到了這一步傳輸才算基本完成。
當然因為傳輸層需要保證可靠性,所以數據包還沒有刪除,此時還有前面的拷貝過的skb指向它,它得等到收到對方的ACK之后才會真正刪除。
六、問題解答查看內核發送數據消耗的CPU時應該看sy還是si
在網絡包發送過程中,用戶進程(在內核態)完成了絕大部分的工作,甚至連調用驅動的工作都干了。只有當內核態進程被切走前才會發起軟中斷。發送過程中百分之九十以上的開銷都是在用戶進程內核態消耗掉的,只有一少部分情況才會觸發軟中斷,有軟中斷ksoftirqd內核線程來發送。所以在監控網絡IO對服務器造成的CPU開銷的時候,不能近看si,而是應該把si、sy(內核占用CPU時間比例)都考慮進來。在服務器上查看/proc/softirqs,為什么NET_RX要比NET_TX大得多
對于讀來說,都是要經過NET_RX軟中斷的,都走ksoftirqd內核線程。而對于發送來說,絕大部份工作都是在用戶進程內核態處理了,只有系統態配額用盡才會發出NET_TX,讓軟中斷處理。當數據發送完以后,通過硬中斷的方式來通知驅動發送完畢。但是硬中斷無論是有數據接收還是發送完畢,觸發的軟中斷都是NET_RX_SOFTIRQ而不是NET_TX_SOFTIRQ。發送網絡數據的時候都涉及那些內存拷貝操作
這里只指內存拷貝內核申請完skb之后,將用戶傳遞進來的buffer里的數據拷貝到skb。如果數據量大,這個拷貝操作還是開銷不小的。從傳輸層進入網絡層時。每個skb都會被克隆出一個新的副本,目的是保存原始的skb,當網絡對方沒有發揮ACK的時候還可以重新發送,易實現TCP中要求的可靠傳輸。不過這次只是淺拷貝,只拷貝skb描述符本身,所指向的數據還是復用的。第三次拷貝不是必須的,只有當IP層發現skb大于MTU時才需要進行,此時會再申請額外的skb,并將原來的skb拷貝成多個小的skb。零拷貝到底是怎么回事
如果想把本機的一個文件通過網絡發送出去,需要先調用read將文件讀到內存,之后再調用send將文件發送出去假設數據之前沒有讀去過,那么read系統調用需要兩次拷貝才能到用戶進程的內存。第一次是從硬盤DMA到Page Cache。第二次是從Page Cache拷貝到內存。send系統調用也同理,先CPU拷貝到socket發送隊列,之后網卡進行DMA拷貝。如果要發送的數據量較大,那么就需要花費不少的時間在數據拷貝上。而sendfile就是內核提供的一個可用來減少發送文件時拷貝開銷的一個技術方案。在sendfile系統調用里,數據不需要拷貝到用戶空間,在內核態就能完成發送處理,減少了拷貝的次數。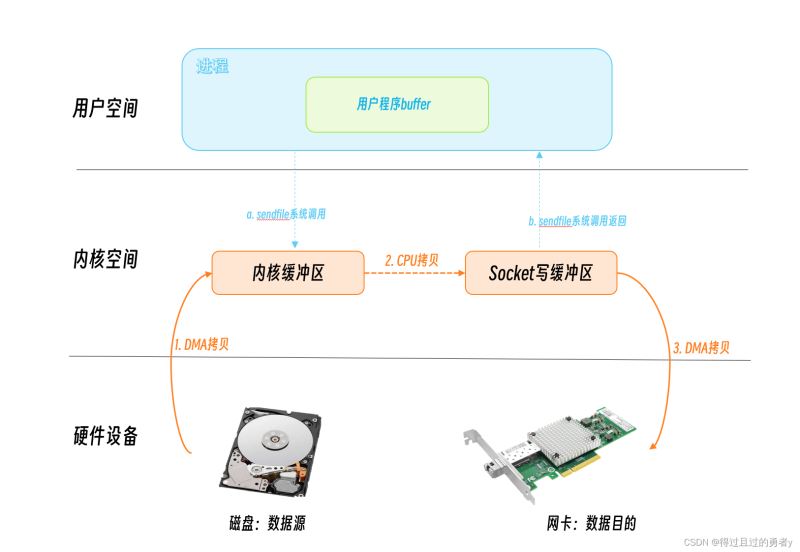
為什么Kafka的網絡性能很突出
Kafka高性能的原因有很多,其中重要的原因之一就是采用了sendfile系統調用來發送網絡數據包,減少了內核態和用戶態之間的頻繁數據拷貝。以上就是深入理解Linux網絡之內核是如何發送網絡包的的詳細內容,更多關于Linux 內核發送網絡包的資料請關注好吧啦網其它相關文章!
 網公網安備
網公網安備