解讀MySQL中一個B+樹能存儲多少數據
目錄
- MySQL中一個B+樹能存儲多少數據
- MySQL聚簇索引的存儲結構
- MySQL中B樹與B+樹的區別
- B樹
- B+樹
- B樹與B+樹的區別
- 總結
MySQL中一個B+樹能存儲多少數據
MySQL聚簇索引的存儲結構
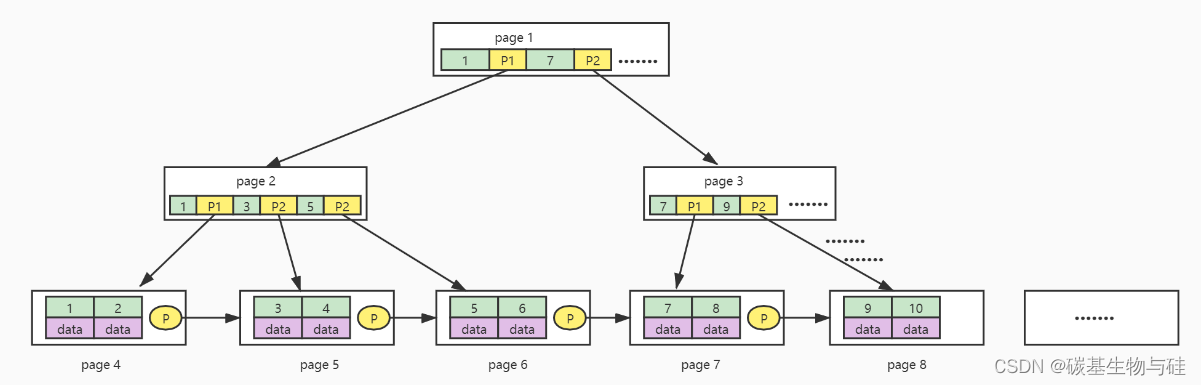
MySQL中InnoDB頁的大小默認是16k。也可以自己進行設置。(計算機在存儲數據的時候,最小存儲單元是扇區,一個扇區的大小是 512 字節,而文件系統(例如 XFS/EXT4)最小單元是塊,一個塊的大小是 4KB。
InnoDB 引擎存儲數據的時候,是以頁為單位的,每個數據頁的大小默認是 16KB,即四個塊。)
在B+樹中,一個結點就是一頁。非葉子結點由主鍵值和一個指向下一層的地址的指針組成的組合組成。葉子結點中由一組鍵值對和一個指向該層下一頁的指針組成,鍵值對存儲的主鍵值和數據。
由存儲結構,可以大概計算出一個B+樹能存儲的數據數量。
指針在InnoDB中為6字節,設主鍵的類型是bigint,占8字節。一組就是14字節。
計算出一個非葉子結點可以存儲16 * 1024 / 14 = 1170個索引指針。
假設一條數據的大小是1KB,那么一個葉子結點可以存儲16條數據。
得出兩層B+樹可以存儲1170 x 16 = 18720 條數據。
三層B+樹可以存儲1170 x 1170 x 16 = 21902400條數據。
MySQL中B樹與B+樹的區別
B樹
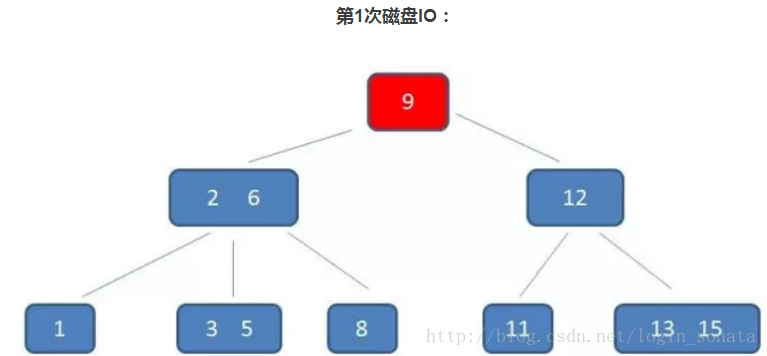
B樹和B+樹都是應用在數據庫索引上,可以認為是m叉的多路平衡查找樹,但是理論上講,二叉樹的查找速度和比較次數都更小,為什么不用二叉樹呢?
這是因為我們要考慮磁盤IO的影響,它相對于內存來說是很慢的,數據庫索引是存儲在磁盤上的,當數據量很大時,就不能把整個索引全部加載到內存中,只能逐一加載每一個磁盤頁(對應索引樹的節點)。
所以我們要減少IO的次數,對于樹來說,IO次數就是樹的高度,而“矮胖”就是B樹的特征之一。
B樹的特征:
- 關鍵字集合分布在整顆樹中;
- 任何一個關鍵字出現且只出現在一個結點中;
- 搜索有可能在非葉子結點結束;
- 其搜索性能等價于在關鍵字全集內做一次二分查找;
B+樹
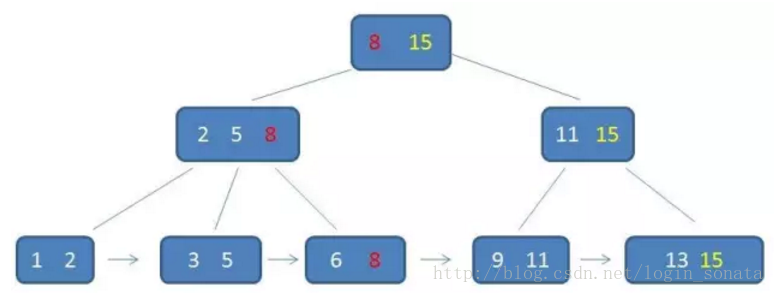
B+樹是B樹的變體,是一種查詢性能更好的B樹。B+樹是一種平衡查找樹。在B+樹中,所有記錄節點都是按鍵值的大小順序存放在同一層的葉節點中,各葉結點指針進行連接。
B+樹的特征:
- 有n棵子樹的非葉子結點中含有n個關鍵字(b樹是n-1個),這些關鍵字不保存數據,只用來索引,所有數據都保存在葉子節點(b樹是每個關鍵字都保存數據)。
- 所有的葉子結點中包含了全部關鍵字的信息,及指向含這些關鍵字記錄的指針,且葉子結點本身依關鍵字的大小自小而大順序鏈接。
- 所有的非葉子結點可以看成是索引部分,結點中僅含其子樹中的最大(或最小)關鍵字。
- 通常在b+樹上有兩個頭指針,一個指向根結點,一個指向關鍵字最小的葉子結點。
- 同一個數字會在不同節點中重復出現,根節點的最大元素就是b+樹的最大元素。
B樹與B+樹的區別
- B樹的中間節點保存節點和數據,B+樹的中間節點不保存數據,數據保存在葉子節點中;所以磁盤頁能容納更多的節點元素,更“矮胖”;
- B樹的查找要只要匹配到元素,就不用管在什么位置,B+樹查找必須匹配到葉子節點,所以B+樹查找更穩定;
- 對于范圍查找到說,B樹要從頭到尾查找,而B+樹只需要在一定的范圍內的葉子節點中查找就可以;
- B+樹的葉子節點通過指針連接,從左到右順序排列;
- B+樹的非葉子節點與葉子節點冗余;
總結
以上為個人經驗,希望能給大家一個參考,也希望大家多多支持。

 網公網安備
網公網安備