Mysql刪除重復(fù)數(shù)據(jù)并且只保留一條(附實(shí)例!)
(1)以這張表為例:
CREATE TABLE `test` ( `id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT "注解id", `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT "名字", PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;INSERT INTO test (id,`name`) VALUES (replace(uuid(),"-",""),"張三"),(replace(uuid(),"-",""),"張三");
表里有兩條數(shù)據(jù),然后名字是相同的,但是id是不同的,現(xiàn)在要求是只留一條數(shù)據(jù):

(2)查詢name值重復(fù)的數(shù)據(jù):
現(xiàn)實(shí)開(kāi)發(fā)當(dāng)中可能一個(gè)字段無(wú)法鎖定重復(fù)值,可以采取group by多個(gè)值!利用多個(gè)值來(lái)鎖定重復(fù)的行數(shù)據(jù)!
SELECT name FROM test GROUP BY `name` HAVING count( name ) > 1
(3)查詢重復(fù)數(shù)據(jù)里面每個(gè)最小的id:
SELECT min(id) as id FROM test GROUP BY `name` HAVING count( name ) > 1
(4)查詢?nèi)サ糁貜?fù)數(shù)據(jù)最小id的其他數(shù)據(jù):也就是要?jiǎng)h除的數(shù)據(jù)!
SELECT * FROM test WHERE name IN ( SELECT name FROM test GROUP BY `name` HAVING count( name ) > 1 ) AND id NOT IN (SELECT min( id ) FROM test GROUP BY `name` HAVING count( NAME ) > 1)
(5)刪除去掉重復(fù)數(shù)據(jù)最小id的其他數(shù)據(jù):
可能這時(shí)候有人該說(shuō)了,有了查詢,直接改成delete不就可以了,真的是這樣嗎?其實(shí)不是的,如下運(yùn)行報(bào)錯(cuò):
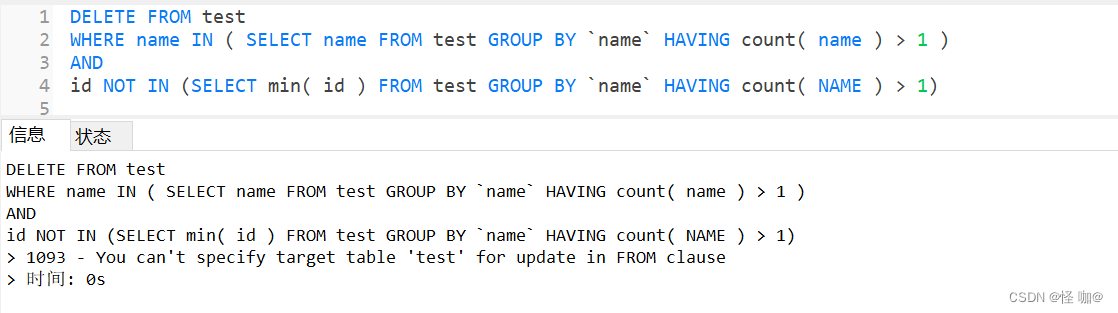
首先明確一點(diǎn)這個(gè)錯(cuò)誤只會(huì)發(fā)生在delete語(yǔ)句或者update語(yǔ)句,拿update來(lái)舉例 : update A表 set A列 = (select B列 from A表); 這種寫(xiě)法就會(huì)報(bào)這個(gè)錯(cuò)誤,原因:你又要修改A表,然后又要從A表查數(shù)據(jù),而且還是同層級(jí)。Mysql就會(huì)認(rèn)為是語(yǔ)法錯(cuò)誤!
嵌套一層就可以解決,update A表 set A列 = (select a.B列 from (select * from A表) a); 當(dāng)然這個(gè)只是個(gè)示例,這個(gè)示例也存在一定的問(wèn)題,比如(select a.B列 from (select * from A表) a)他會(huì)查出來(lái)多條,然后賦值的時(shí)候會(huì)報(bào) 1242 - Subquery returns more than 1 row。
嵌套一層他就可以和update撇清關(guān)系,會(huì)優(yōu)先查括號(hào)里面的內(nèi)容,查詢結(jié)果出來(lái)過(guò)后會(huì)給存起來(lái),類似臨時(shí)表,可能有的人該好奇了,update A表 set A列 = (select B列 from A表); 我明明加括號(hào)了呀,難道不算嵌套嗎,當(dāng)然不算,那個(gè)括號(hào)根本沒(méi)有解決他們之間的層次關(guān)系!
詳解看這篇文章:https://www.jb51.net/article/274025.htm
(6)正確的寫(xiě)法:
方式一:
DELETE FROM test WHERE name IN ( select a.name from (SELECT name FROM test GROUP BY `name` HAVING count( name ) > 1) a) AND id NOT IN (select a.id from (SELECT min(id) as id FROM test GROUP BY `name` HAVING count( name ) > 1) a)
注意:刪除之前一定要先查詢,然后再刪除,否則一旦語(yǔ)法有問(wèn)題導(dǎo)致刪了不想刪除的數(shù)據(jù),想要恢復(fù)很麻煩!或者刪除前備份好數(shù)據(jù),不要嫌麻煩,一旦出問(wèn)題,才是真正的大麻煩!
方式二:
DELETE FROM test WHERE id NOT IN ( SELECT t.id FROM ( SELECT MIN(id) as id FROM test GROUP BY NAME ) t)
(7)錯(cuò)誤的寫(xiě)法: 這塊我吃過(guò)一次虧,所以專門(mén)寫(xiě)出來(lái),避免踩坑!
千萬(wàn)千萬(wàn)不能這么搞,下面這個(gè)語(yǔ)法相當(dāng)于是先按name分組,然后查出來(lái)大于1的,這時(shí)候假如大于1的有很多,然后外面嵌套的那一層,只取了最小的一條數(shù)據(jù),然后再加上使用的是
NOT IN,最終會(huì)導(dǎo)致數(shù)據(jù)全部被刪除!!!

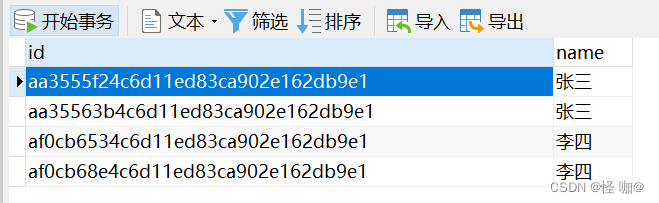
執(zhí)行前有四條數(shù)據(jù),實(shí)際上我們要的是張三留下來(lái)一條,然后李四留下來(lái)一條
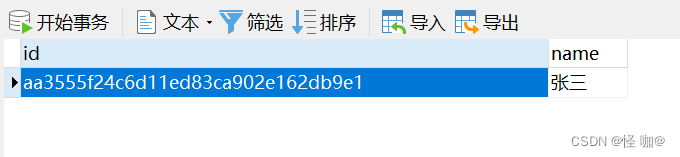
執(zhí)行結(jié)果:只留下了一條!
總結(jié)
到此這篇關(guān)于Mysql刪除重復(fù)數(shù)據(jù)并且只保留一條的文章就介紹到這了,更多相關(guān)Mysql刪除重復(fù)數(shù)據(jù)只保留一條內(nèi)容請(qǐng)搜索以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持!

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備