文章詳情頁
ORACLE中常用的幾種正則表達式小結
瀏覽:173日期:2023-03-12 15:25:15
ORACLE正則表達式我基本用到的就一下幾種,前四種最長用到
- REGEXP_LIKE(source_char, pattern, match_parameter)
- REGEXP_SUBSTR(source_char, pattern, position, occurrence,match_parameter)
- REGEXP_INSTR(source_char, pattern, position, occurrence,match_parameter)
- REGEXP_REPLACE
- REGEXP_COUNT
- REGEXP_EXTRACT
- REGEXP_MATCH_COUNT
分享之前先給大家講講這些參數
1、source_char,輸入的字符串,可以是列名或者字符串常量、變量。
2、pattern,正則表達式。
3、match_parameter,匹配選項。
match_parameter的取值模式:
i:大小寫不敏感;
c:大小寫敏感;
n:點號 . 不匹配換行符號;
m:多行模式;
x:擴展模式,忽略正則表達式中的空白字符。
4、position,標識從第幾個字符開始正則表達式匹配。
5、occurrence:標識第幾個匹配組。
6、return_option:
0:pattern的起始位置 ,1:pattern下一個字符起始位置, 默認為0
7、replace_string,替換的字符串。
下面我給大家介紹第一種
1.REGEXP_LIKE標量函數
REGEXP_LIKE標量函數返回一個布爾值,該布爾值指示是否在字符串中找到了正則表達式模式。這個函數和LIKE函數幾乎很相近,只是LIKE函數匹配的是具體的字符或者數字,而這個函數匹配的是正則表達式。
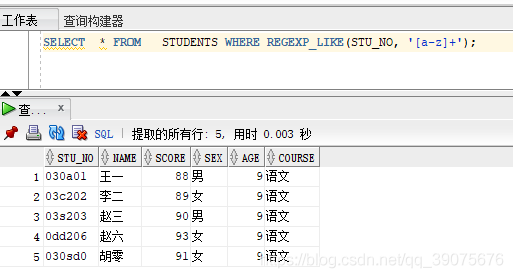
例如一張學生表中的學號既有全數字的也有數字字符混在的,現在學校希望將有字符混在的學號跳出來,這事就這可以用這個函數
表數據如下:

SELECT * FROM STUDENTS WHERE REGEXP_LIKE(STU_NO, "[a-z]+");
下面就是我們抽取的對象
其他幾種用法比較類似,就不一一說明了。
補充:綜合應用的例子
col row_line format a30;with sudoku as ( select "020000080568179234090000010030040050040205090070080040050000060289634175010000020" as line from dual),tmp as ( select regexp_substr(line,"\d{9}",1,level) row_line, level col from sudoku connect by level<=9)select regexp_replace( row_line ,"(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)","\1 \2 \3 \4 \5 \6 \7 \8 \9") row_linefrom tmp; ROW_LINE------------------------------0 2 0 0 0 0 0 8 05 6 8 1 7 9 2 3 40 9 0 0 0 0 0 1 00 3 0 0 4 0 0 5 00 4 0 2 0 5 0 9 00 7 0 0 8 0 0 4 00 5 0 0 0 0 0 6 02 8 9 6 3 4 1 7 50 1 0 0 0 0 0 2 0總結
到此這篇關于ORACLE中常用的幾種正則表達式的文章就介紹到這了,更多相關ORACLE正則表達式內容請搜索以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持!
標簽:
Oracle
排行榜

 網公網安備
網公網安備