Python中jieba庫的使用方法
jieba庫是一款優(yōu)秀的 Python 第三方中文分詞庫,jieba 支持三種分詞模式:精確模式、全模式和搜索引擎模式,下面是三種模式的特點。
精確模式:試圖將語句最精確的切分,不存在冗余數(shù)據(jù),適合做文本分析
全模式:將語句中所有可能是詞的詞語都切分出來,速度很快,但是存在冗余數(shù)據(jù)
搜索引擎模式:在精確模式的基礎(chǔ)上,對長詞再次進行切分
一、jieba庫的安裝因為 jieba 是一個第三方庫,所有需要我們在本地進行安裝。
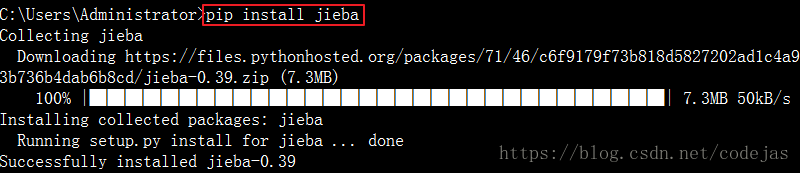
Windows 下使用命令安裝:在聯(lián)網(wǎng)狀態(tài)下,在命令行下輸入 pip install jieba 進行安裝,安裝完成后會提示安裝成功
在 pyCharm 中安裝:打開 settings,搜索 Project Interpreter,在右邊的窗口選擇 + 號,點擊后在搜索框搜索 jieba,點擊安裝即可
二、jieba三種模式的使用# -*- coding: utf-8 -*-import jiebaseg_str = '好好學(xué)習(xí),天天向上。'print('/'.join(jieba.lcut(seg_str))) # 精簡模式,返回一個列表類型的結(jié)果print('/'.join(jieba.lcut(seg_str, cut_all=True))) # 全模式,使用 ’cut_all=True’ 指定 print('/'.join(jieba.lcut_for_search(seg_str))) # 搜索引擎模式
分詞效果:

需求:使用 jieba 分詞對一個文本進行分詞,統(tǒng)計次數(shù)出現(xiàn)最多的詞語,這里以三國演義為例
# -*- coding: utf-8 -*-import jiebatxt = open('三國演義.txt', 'r', encoding=’utf-8’).read()words = jieba.lcut(txt) # 使用精確模式對文本進行分詞counts = {} # 通過鍵值對的形式存儲詞語及其出現(xiàn)的次數(shù)for word in words: if len(word) == 1: # 單個詞語不計算在內(nèi)continue else:counts[word] = counts.get(word, 0) + 1 # 遍歷所有詞語,每出現(xiàn)一次其對應(yīng)的值加 1items = list(counts.items())items.sort(key=lambda x: x[1], reverse=True) # 根據(jù)詞語出現(xiàn)的次數(shù)進行從大到小排序for i in range(3): word, count = items[i] print('{0:<5}{1:>5}'.format(word, count))
統(tǒng)計結(jié)果:

你可以隨便找一個文本文檔,也可以到 https://github.com/coderjas/python-quick 下載上面例子中的文檔。
四、擴展:英文單詞統(tǒng)計上面的例子統(tǒng)計實現(xiàn)了中文文檔中出現(xiàn)最多的詞語,接著我們就來統(tǒng)計一下一個英文文檔中出現(xiàn)次數(shù)最多的單詞。原理同上
# -*- coding: utf-8 -*-def get_text(): txt = open('1.txt', 'r', encoding=’UTF-8’).read() txt = txt.lower() for ch in ’!'#$%&()*+,-./:;<=>?@[]^_‘{|}~’:txt = txt.replace(ch, ' ') # 將文本中特殊字符替換為空格 return txtfile_txt = get_text()words = file_txt.split() # 對字符串進行分割,獲得單詞列表counts = {}for word in words: if len(word) == 1:continue else:counts[word] = counts.get(word, 0) + 1 items = list(counts.items()) items.sort(key=lambda x: x[1], reverse=True) for i in range(5): word, count = items[i] print('{0:<5}->{1:>5}'.format(word, count))
統(tǒng)計結(jié)果:

到此這篇關(guān)于Python中jieba庫的使用方法的文章就介紹到這了,更多相關(guān)Python jieba庫內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Struts2獲取參數(shù)的三種方法總結(jié)2. JSP中Servlet的Request與Response的用法與區(qū)別3. IntelliJ IDEA刪除類的方法步驟4. js select支持手動輸入功能實現(xiàn)代碼5. Android 實現(xiàn)徹底退出自己APP 并殺掉所有相關(guān)的進程6. vue cli4下環(huán)境變量和模式示例詳解7. vue使用moment如何將時間戳轉(zhuǎn)為標準日期時間格式8. Django視圖類型總結(jié)9. IntelliJ IDEA導(dǎo)入jar包的方法10. Xml簡介_動力節(jié)點Java學(xué)院整理
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備