django haystack實現全文檢索的示例代碼
全文檢索里的組件簡介
1. 什么是haystack?
1. haystack是django的開源搜索框架,該框架支持Solr,Elasticsearch,Whoosh, *Xapian*搜索引擎,不用更改代碼,直接切換引擎,減少代碼量。
2. 搜索引擎使用Whoosh,這是一個由純Python實現的全文搜索引擎, 沒有二進制文件等,比較小巧,配置比較簡單,當然性能自然略低。
3. 中文分詞Jieba,由于Whoosh自帶的是英文分詞,對中文的分詞支持不是太好,故用jieba替換whoosh的分詞組件
2. 什么是jieba?
很多的搜索引擎對中的支持不友好,jieba作為一個中文分詞器就是加強對中文的檢索功能
3. Whoosh是什么
1. Python的全文搜索庫,Whoosh是索引文本及搜索文本的類和函數庫
2. Whoosh 自帶的是英文分詞,對中文分詞支持不太好,使用 jieba 替換 whoosh 的分詞組件。
haystack配置使用(前后端分離)
1. 安裝需要的包
pip3 install django-haystackpip3 install whooshpip3 install jieba
2. 在setting.py中配置
’’’注冊app ’’’INSTALLED_APPS = [ ’django.contrib.admin’, ’django.contrib.auth’, ’django.contrib.contenttypes’, ’django.contrib.sessions’, ’django.contrib.messages’, ’django.contrib.staticfiles’, # haystack要放在應用的上面 ’haystack’, ’myapp’, # 這個jsapp是自己創建的app]’’’配置haystack ’’’# 全文檢索框架配置HAYSTACK_CONNECTIONS = { ’default’: { # 指定whoosh引擎 ’ENGINE’: ’haystack.backends.whoosh_backend.WhooshEngine’, # ’ENGINE’: ’myapp.whoosh_cn_backend.WhooshEngine’, # whoosh_cn_backend是haystack的whoosh_backend.py改名的文件為了使用jieba分詞 # 索引文件路徑 ’PATH’: os.path.join(BASE_DIR, ’whoosh_index’), }}# 添加此項,當數據庫改變時,會自動更新索引,非常方便HAYSTACK_SIGNAL_PROCESSOR = ’haystack.signals.RealtimeSignalProcessor’
3. 定義數據庫
from django.db import models# Create your models here.class UserInfo(models.Model): name = models.CharField(max_length=254) age = models.IntegerField()class ArticlePost(models.Model): author = models.ForeignKey(UserInfo,on_delete=models.CASCADE) title = models.CharField(max_length=200) desc = models.SlugField(max_length=500) body = models.TextField()
索引文件生成
1. 在子應用下創建索引文件
在子應用的目錄下,創建一個名為 myapp/search_indexes.py 的文件
from haystack import indexesfrom .models import ArticlePost# 修改此處,類名為模型類的名稱+Index,比如模型類為GoodsInfo,則這里類名為GoodsInfoIndex(其實可以隨便寫)class ArticlePostIndex(indexes.SearchIndex, indexes.Indexable): # text為索引字段 # document = True,這代表haystack和搜索引擎將使用此字段的內容作為索引進行檢索 # use_template=True 指定根據表中的那些字段建立索引文件的說明放在一個文件中 text = indexes.CharField(document=True, use_template=True) # 對那張表進行查詢 def get_model(self): # 重載get_model方法,必須要有! # 返回這個model return ArticlePost # 建立索引的數據 def index_queryset(self, using=None): # 這個方法返回什么內容,最終就會對那些方法建立索引,這里是對所有字段建立索引 return self.get_model().objects.all()
2.指定索引模板文件
創建文件路徑命名必須這個規范:templates/search/indexes/應用名稱/模型類名稱_text.txt如:templates/search/indexes/myapp/articlepost_text.txt
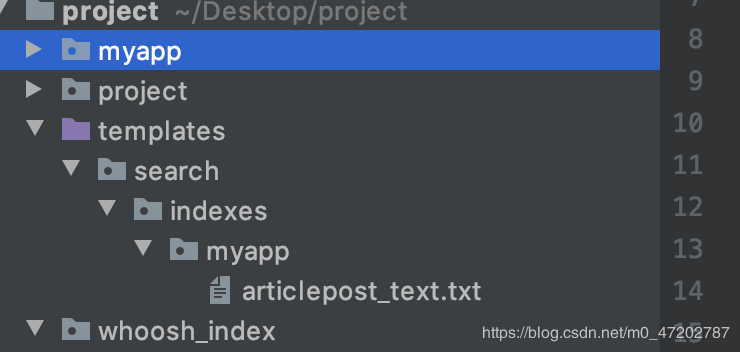
{{ object.title }}{{ object.author.name }}{{ object.body }}
3.使用命令創建索引
python manage.py rebuild_index # 建立索引文件
替換成jieba分詞
1.將haystack源碼復制到項目中并改名
’’’1.復制源碼中文件并改名 ’’’將 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/haystack/backends/whoosh_backend.py文件復制到項目中并將 whoosh_backend.py改名為 whoosh_cn_backend.py 放在APP中如:myappwhoosh_cn_backend.py’’’2.修改源碼中文件’’’# 在全局引入的最后一行加入jieba分詞器from jieba.analyse import ChineseAnalyzer# 修改為中文分詞法查找analyzer=StemmingAnalyzer()改為analyzer=ChineseAnalyzer()
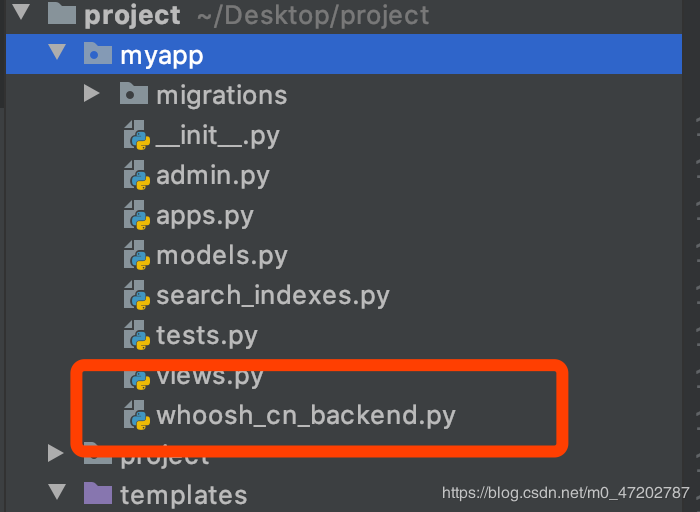
索引文件使用
1. 編寫視圖
from django.shortcuts import render# Create your views here.import jsonfrom django.conf import settingsfrom django.core.paginator import InvalidPage, Paginatorfrom django.http import Http404, HttpResponse,JsonResponsefrom haystack.forms import ModelSearchFormfrom haystack.query import EmptySearchQuerySetRESULTS_PER_PAGE = getattr(settings, ’HAYSTACK_SEARCH_RESULTS_PER_PAGE’, 20)def basic_search(request, load_all=True, form_class=ModelSearchForm, searchqueryset=None, extra_context=None, results_per_page=None): query = ’’ results = EmptySearchQuerySet() if request.GET.get(’q’): form = form_class(request.GET, searchqueryset=searchqueryset, load_all=load_all) if form.is_valid(): query = form.cleaned_data[’q’] results = form.search() else: form = form_class(searchqueryset=searchqueryset, load_all=load_all) paginator = Paginator(results, results_per_page or RESULTS_PER_PAGE) try: page = paginator.page(int(request.GET.get(’page’, 1))) except InvalidPage: result = {'code': 404, 'msg': ’No file found!’, 'data': []} return HttpResponse(json.dumps(result), content_type='application/json') context = { ’form’: form, ’page’: page, ’paginator’: paginator, ’query’: query, ’suggestion’: None, } if results.query.backend.include_spelling: context[’suggestion’] = form.get_suggestion() if extra_context: context.update(extra_context) jsondata = [] print(len(page.object_list)) for result in page.object_list: data = { ’pk’: result.object.pk, ’title’: result.object.title, ’content’: result.object.body, } jsondata.append(data) result = {'code': 200, 'msg': ’Search successfully!’, 'data': jsondata} return JsonResponse(result, content_type='application/json')
到此這篇關于django haystack實現全文檢索的示例代碼的文章就介紹到這了,更多相關django haystack 全文檢索內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備