Django-Scrapy生成后端json接口的方法示例
網上的關于django-scrapy的介紹比較少,該博客只在本人查資料的過程中學習的,如果不對之處,希望指出改正;
以后的博客可能不會再出關于django相關的點;
人心太浮躁,個人深度不夠,只學習了一些皮毛,后面博客只求精,不求多;
希望能堅持下來。加油!
學習點:
實現效果 django與scrapy的創建 setting中對接的位置和代碼段 scrapy_djangoitem使用 scrapy數據爬取保存部分 數據庫設計以及問題部分 django配置實現效果:
django與scrapy的創建:
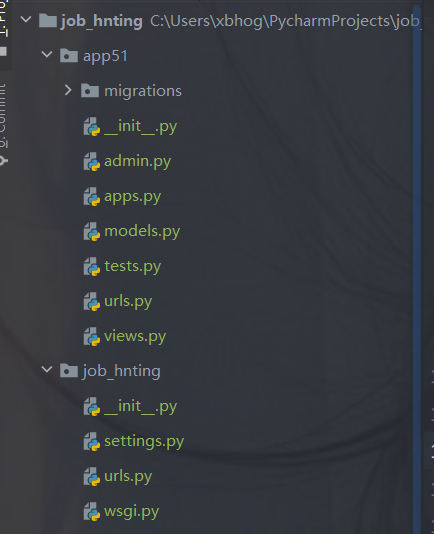
django的創建:
django startproject 項目名稱
cd 項目名稱python manage.py startapp appname
例如:
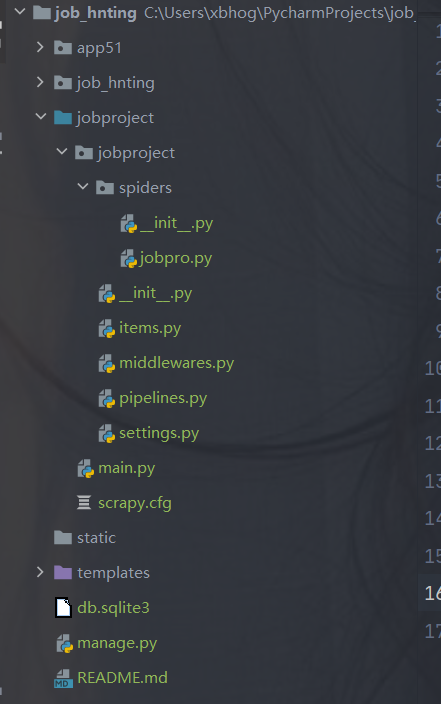
scrapy的創建:
# cd django的根目錄下cd job_hntingscrapy startproject 項目名稱#創建爬蟲scrapy genspider spidername ’www.xxx.com’
例如:
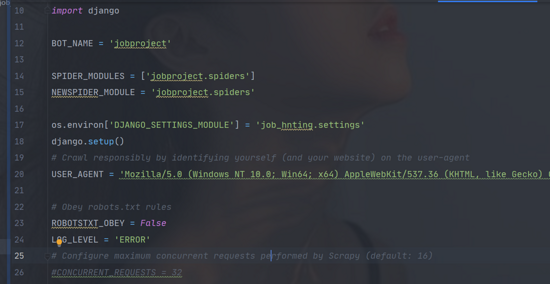
setting的設置:
在scrapy框架中的setting指向django,讓django知道有scrapy;
在scrapy中的setting設置;
import osimport django#導入os.environ[’DJANGO_SETTINGS_MODULE’] = ’job_hnting.settings’#手動初始化django.setup()
如:
scrapy_djangoitem使用:
pip install scrapy_djangoitem
該庫在scrapy項目下的item中編寫引入:
import scrapy# 引入django中app中models文件中的類from app51.models import app51data# scrapy與django對接的庫from scrapy_djangoitem import DjangoItemclass JobprojectItem(DjangoItem): #引用django下的model中的類名 django_model = app51data
數據存儲部分對接在后面解釋,現在大體框架完整;
scrapy爬取保存部分:
首先編寫scrapy爬蟲部分:
我們選取的是51招聘網站的數據:
爬取分為三個函數:
主函數 解析函數 總頁數函數51job的反爬手段:
將json的數據格式隱藏在網頁結構中,網上教程需要別的庫解析(自行了解),
我們的方法是使用正則匹配提取定位到數據部分,使用json庫解析:
# 定位數據位置,提取json數據 search_pattern = 'window.__SEARCH_RESULT__ = (.*?)</script>' jsonText = re.search(search_pattern, response.text, re.M | re.S).group(1)
獲得關鍵字總頁數:
# 解析json數據 jsonObject = json.loads(jsonText) number = jsonObject[’total_page’]
在主函數中構造頁面url并給到解析函數:
for number in range(1,int(numbers)+1): next_page_url = self.url.format(self.name,number) # print(next_page_url) #構造的Urlcallback到data_parse函數中 yield scrapy.Request(url=next_page_url,callback=self.data_parse)
最后在解析函數中提取需要的數據:
for job_item in jsonObject['engine_search_result']: items = JobprojectItem() items[’job_name’] = job_item[’job_name’] items[’company_name’] = job_item['company_name'] # 發布時間 items[’Releasetime’] = job_item[’issuedate’] items[’salary’] = job_item[’providesalary_text’] items[’site’] = job_item[’workarea_text’] .......
相關的細節部分需要自己調整,完整代碼在 GitHub 中。
數據爬取部分解決后,需要到scrapy項目中的pipline文件保存;
class SeemeispiderPipeline(object): def process_item(self, item, spider): item.save() return item
記得在setting文件中取消掉pipline的注釋
設置數據庫:
Django配置數據庫有兩種方法:
方法一:直接在settings.py文件中添加數據庫配置信息(個人使用的)
DATABASES = { # 方法一 ’default’: { ’ENGINE’: ’django.db.backends.mysql’, # 數據庫引擎 ’NAME’: ’mysite’, # 數據庫名稱 ’USER’: ’root’, # 數據庫登錄用戶名 ’PASSWORD’: ’123’,# 密碼 ’HOST’: ’127.0.0.1’,# 數據庫主機IP,如保持默認,則為127.0.0.1 ’PORT’: 3306, # 數據庫端口號,如保持默認,則為3306 }}
方法二:將數據庫配置信息存到一個文件中,在settings.py文件中將其引入。
新建數據庫配置文件my.cnf(名字隨意選擇)
[client]database = bloguser = blogpassword = bloghost =127.0.0.1port = 3306default-character-set = utf8
在settings.py文件中引入my.cnf文件
DATABASES = { # 方法二: ’default’: { ’ENGINE’: ’django.db.backends.mysql’, ’OPTIONS’: { ’read_default_file’: ’utils/dbs/my.cnf’, }, }}
啟用Django與mysql的連接
在生產環境中安裝pymysql 并且需要在settings.py文件所在包中的 __init__.py 中導入pymysql
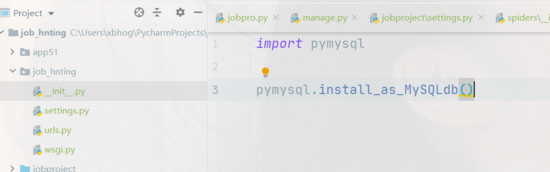
import pymysqlpymysql.install_as_MySQLdb()
對應前面的item,在spider中編寫時按照model設置的即可;;
from django.db import models# Create your models here.#定義app51的數據模型class app51data(models.Model): #發布時間,長度20 Releasetime = models.CharField(max_length=20) #職位名,長度50 job_name =models.CharField(max_length=50) #薪水 salary = models.CharField(max_length=20) #工作地點 site = models.CharField(max_length=50) #學歷水平 education = models.CharField(max_length=20) #公司名稱 company_name = models.CharField(max_length=50) #工作經驗 Workexperience = models.CharField(max_length=20) #指定表名 class Meta: db_table = ’jobsql51’ def __str__(self): return self.job_name
當指定完表名后,在DBMS中只需要創建對應的數據庫即可,表名自動創建
每次修改數據庫都要進行以下命令:
python manage.py makemigrationspython manage.py migrate
到此mysql數據庫配置完成
配置數據庫時遇到的錯誤:
Django啟動報錯:AttributeError: ’str’ object has no attribute ’decode’
解決方法:
找到Django安裝目錄
G:envdjango_jobLibsite-packagesdjangodbbackendsmysqloperations.py
編輯operations.py;
將146行的decode修改成encode
def last_executed_query(self, cursor, sql, params): # With MySQLdb, cursor objects have an (undocumented) '_executed' # attribute where the exact query sent to the database is saved. # See MySQLdb/cursors.py in the source distribution. query = getattr(cursor, ’_executed’, None) if query is not None: #query = query.decode(errors=’replace’) uery = query.encode(errors=’replace’) return query
django配置:
關于django的基礎配置,如路由,app的注冊等基礎用法,暫時不過多說明;
以下主要關于APP中視圖的配置,生成json;
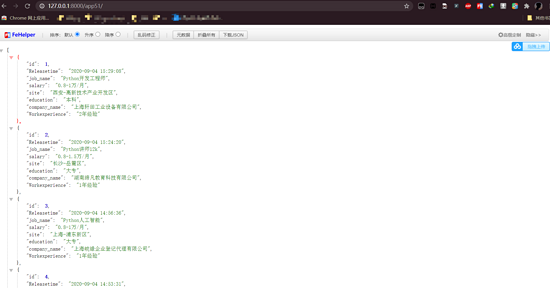
from django.shortcuts import renderfrom django.http import HttpResponse# Create your views here.#引入數據from .models import app51dataimport jsondef index(request): # return HttpResponse('hello world') # return render(request,’index.html’) #獲取所有的對象,轉換成json格式 data =app51data.objects.all() list3 = [] i = 1 for var in data: data = {} data[’id’] = i data[’Releasetime’] = var.Releasetime data[’job_name’] = var.job_name data[’salary’] = var.salary data[’site’] = var.site data[’education’] = var.education data[’company_name’] = var.company_name data[’Workexperience’] = var.Workexperience list3.append(data) i += 1 # a = json.dumps(data) # b = json.dumps(list2) # 將集合或字典轉換成json 對象 c = json.dumps(list3) return HttpResponse(c)
實現效果:
完整代碼在 GitHub 中,希望隨手star,感謝!
到此這篇關于Django-Scrapy生成后端json接口的方法示例的文章就介紹到這了,更多相關Django Scrapy生成json接口內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:

 網公網安備
網公網安備