SpringBoot整合Redis正確的實現分布式鎖的示例代碼
前言
最近在做分塊上傳的業務,使用到了Redis來維護上傳過程中的分塊編號。
每上傳完成一個分塊就獲取一下文件的分塊集合,加入新上傳的編號,手動接口測試下是沒有問題的,前端通過并發上傳調用就出現問題了,并發的get再set,就會存在覆蓋寫現象,導致最后的分塊數據不對,不能觸發分塊合并請求。
遇到并發二話不說先上鎖,針對執行代碼塊加了一個JVM鎖之后問題就解決了。
仔細一想還是不太對,項目是分布式部署的,做了負載均衡,一個節點的代碼被鎖住了,請求輪詢到其他節點還是可以進行覆蓋寫,并沒有解決到問題啊
沒辦法,只有用上分布式鎖了。之前對于分布式鎖的理論還是很熟悉的,沒有比較好的應用場景就沒寫過具體代碼,趁這個機會就學習使用一下分布式鎖。
理論
分布式鎖是控制分布式系統之間同步訪問共享資源的一種方式。是為了解決分布式系統中,不同的系統或是同一個系統的不同主機共享同一個資源的問題,它通常會采用互斥來保證程序的一致性
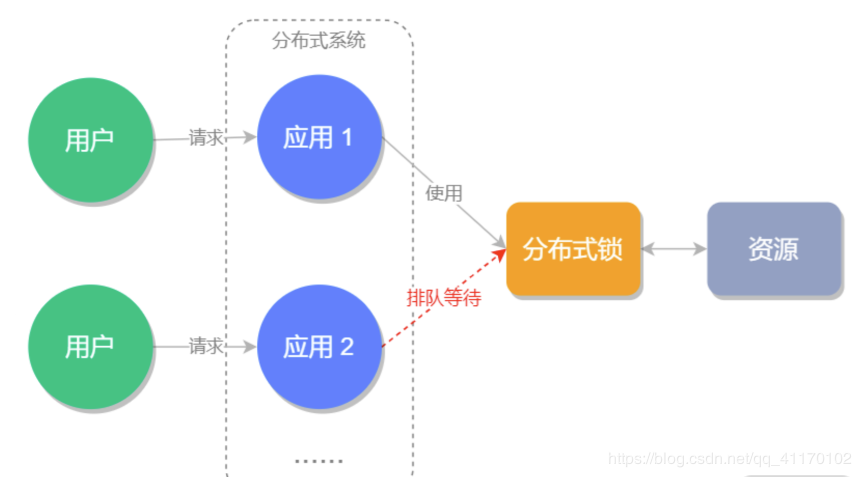
通常的實現方式有三種:
基于 MySQL 的悲觀鎖來實現分布式鎖,這種方式使用的最少,這種實現方式的性能不好,且容易造成死鎖,并且MySQL本來業務壓力就很大了,再做鎖也不太合適 基于 Redis 實現分布式鎖,單機版可用setnx實現,多機版建議用Radission 基于 ZooKeeper 實現分布式鎖,利用 ZooKeeper 順序臨時節點來實現為了確保分布式鎖可用,我們至少要確保鎖的實現同時滿足以下四個條件:
互斥性。在任意時刻,只有一個客戶端能持有鎖。 不會發生死鎖。即使有一個客戶端在持有鎖的期間崩潰而沒有主動解鎖,也能保證后續其他客戶端能加鎖。 具有容錯性。只要大部分的Redis節點正常運行,客戶端就可以加鎖和解鎖。 解鈴還須系鈴人。加鎖和解鎖必須是同一個客戶端,客戶端自己不能把別人加的鎖給解了。本文就使用的是Redis的setnx實現,如果Redis是多機版的可以去了解下Radssion,封裝的就特別的好,也是官方推薦的
代碼
1. 加依賴
引入Spring Boot和Redis整合的快速使用依賴
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
2. 加配置
application.properties中加入Redis連接相關配置
spring.redis.host=xxxspring.redis.port=6379spring.redis.database=0spring.redis.password=xxxspring.redis.timeout=10000# 設置jedis連接池spring.redis.jedis.pool.max-active=50spring.redis.jedis.pool.min-idle=20
3. 重寫Redis的序列化規則
默認使用的JDK的序列化,不自己設置一下Redis中的數據是看不懂的
/** * @author Chkl * @create 2020/6/7 * @since 1.0.0 */@Componentpublic class RedisConfig { /** * 改造RedisTemplate,重寫序列化規則,避免存入序列化內容看不懂 * @param connectionFactory * @return */ @Bean public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) { RedisTemplate redisTemplate = new RedisTemplate(); redisTemplate.setConnectionFactory(connectionFactory); // 設置key和value的序列化規則 redisTemplate.setValueSerializer(new Jackson2JsonRedisSerializer(Object.class)); redisTemplate.setKeySerializer(new StringRedisSerializer()); return redisTemplate; }}
4. 如何正確的上鎖
直接上代碼
@Componentpublic class RedisLock { @Autowired private StringRedisTemplate redisTemplate; private long timeout = 3000; /** * 上鎖 * @param key 鎖標識 * @param value 線程標識 * @return 上鎖狀態 */ public boolean lock(String key, String value) { long start = System.currentTimeMillis(); while (true) { //檢測是否超時 if (System.currentTimeMillis() - start > timeout) {return false; } //執行set命令 Boolean absent = redisTemplate.opsForValue().setIfAbsent(key, value, timeout, TimeUnit.MILLISECONDS);//1 //是否成功獲取鎖 if (absent) {return true; } return false; } }}
核心代碼就是
Boolean absent = redisTemplate.opsForValue().setIfAbsent(key, value, timeout, TimeUnit.MILLISECONDS);
setIfAbsent方法就相當于命令行下的Setnx方法,指定的 key 不存在時,為 key 設置指定的值
參數分別是key、value、超時時間和時間單位
key,表示針對于這段資源的唯一標識 value,表示針對于這個線程的唯一標識。為什么有了key了還需要設置value呢,就是為了滿足四個條件的最后一個:解鈴還須系鈴人。只有通過key和value的組合才能保證解鎖時是同一個線程來解鎖 超時時間,必須和setnx一起進行操作,不能再setnx結束后再執行。如果加鎖成功了,還沒有設置過期時間就宕機了,鎖就永遠不會過期,變成死鎖5. 如何正確解鎖
@Componentpublic class RedisLock { @Autowired private StringRedisTemplate redisTemplate; @Autowired private DefaultRedisScript<Long> redisScript; private static final Long RELEASE_SUCCESS = 1L; /** * 解鎖 * @param key 鎖標識 * @param value 線程標識 * @return 解鎖狀態 */ public boolean unlock(String key, String value) { //使用Lua腳本:先判斷是否是自己設置的鎖,再執行刪除 Long result = redisTemplate.execute(redisScript, Arrays.asList(key,value)); //返回最終結果 return RELEASE_SUCCESS.equals(result); } /** * @return lua腳本 */ @Bean public DefaultRedisScript<Long> defaultRedisScript() { DefaultRedisScript<Long> defaultRedisScript = new DefaultRedisScript<>(); defaultRedisScript.setResultType(Long.class); defaultRedisScript.setScriptText('if redis.call(’get’, KEYS[1]) == KEYS[2] then return redis.call(’del’, KEYS[1]) else return 0 end'); return defaultRedisScript; }}
解鎖過程需要兩步操作
1.判斷操作線程是否是加鎖的線程2.如果是加鎖線程,執行解鎖操作
這兩步操作也需要原子的進行操作,但是Redis不支持這兩步的合并的操作,所以,就只有使用lua腳本實現來保證原子性咯如果在判斷是加鎖的線程之后,并且執行解鎖之前,鎖到期了,被其他線程獲得鎖了,這時候再進行解鎖就會解掉其他線程的鎖,使得不滿足解鈴還須系鈴人
6. 實際應用
沒有使用分布式鎖時的保存文件分塊的代碼
/** * 保存文件分塊編號到redis * @param chunkNumber 分塊號 * @param identifier 文件唯一編號 * @return 文件分塊的大小 */ @Override public Integer saveChunk(Integer chunkNumber, String identifier) { //從Redis獲取已經存在的分塊編號集合 Set<Integer> oldChunkNumber = (Set<Integer>) JSON.parseObject(redisOperator.get('chunkNumberList_'+identifier),Set.class); //如果不存在分塊集合,創建一個集合 if (Objects.isNull(oldChunkNumber)) { Set<Integer> newChunkNumber = new HashSet<>(); newChunkNumber.add(chunkNumber); redisOperator.set('chunkNumberList_'+identifier, JSON.toJSONString(newChunkNumber),36000); return newChunkNumber.size(); //如果分塊集合已經存在了,就添加一個編號 } else { oldChunkNumber.add(chunkNumber); redisOperator.set('chunkNumberList_'+identifier, JSON.toJSONString(oldChunkNumber),36000); return oldChunkNumber.size(); } }
存在的問題是:當并發的請求進來之后,可能獲取同一個狀態的集合進行修改,修改后直接寫入,造成同一個狀態獲得的集合操作線程覆蓋寫的現象
使用分布式鎖保證同時只能有一個線程能獲取到集合并進行修改,避免了覆蓋寫現象
使用分布式鎖代碼
/** * 保存文件分塊編號到redis * @param chunkNumber 分塊號 * @param identifier 文件唯一編號 * @return 文件分塊的大小 */ @Override public Integer saveChunk(Integer chunkNumber, String identifier) { //通過UUID生成一個請求線程識別標志作為鎖的value String threadUUID = CoreUtil.getUUID(); //上鎖,以共享資源標識:文件唯一編號,作為key,以線程標識UUID作為value redisLock.lock(identifier,threadUUID); //從Redis獲取已經存在的分塊編號集合 Set<Integer> oldChunkNumber = (Set<Integer>) JSON.parseObject(redisOperator.get('chunkNumberList_'+identifier),Set.class); //如果不存在分塊集合,創建一個集合 if (Objects.isNull(oldChunkNumber)) { Set<Integer> newChunkNumber = new HashSet<>(); newChunkNumber.add(chunkNumber); redisOperator.set('chunkNumberList_'+identifier, JSON.toJSONString(newChunkNumber),36000); //解鎖 redisLock.unlock(identifier,threadUUID); return newChunkNumber.size(); //如果分塊集合已經存在了,就添加一個編號 } else { oldChunkNumber.add(chunkNumber); redisOperator.set('chunkNumberList_'+identifier, JSON.toJSONString(oldChunkNumber),36000); //解鎖 redisLock.unlock(identifier,threadUUID); return oldChunkNumber.size(); } }
代碼中使用的共享資源標識是文件唯一編號identifier,它能標識加鎖代碼段中的唯一資源,即key為'chunkNumberList_'+identifier的集合
代碼中使用的線程唯一標識是UUID,能保證加鎖和解鎖時獲取的標識不會重復
到此這篇關于SpringBoot整合Redis正確的實現分布式鎖的示例代碼的文章就介紹到這了,更多相關SpringBoot整合Redis分布式鎖內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備