python爬蟲學習筆記之Beautifulsoup模塊用法詳解
本文實例講述了python爬蟲學習筆記之Beautifulsoup模塊用法。分享給大家供大家參考,具體如下:
相關內容: 什么是beautifulsoup bs4的使用 導入模塊 選擇使用解析器 使用標簽名查找 使用findfind_all查找 使用select查找首發時間:2018-03-02 00:10
什么是beautifulsoup: 是一個可以從HTML或XML文件中提取數據的Python庫.它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式.(官方) beautifulsoup是一個解析器,可以特定的解析出內容,省去了我們編寫正則表達式的麻煩。Beautiful Soup 3 目前已經停止開發,我們推薦在現在的項目中使用Beautiful Soup 4
beautifulsoup的版本:最新版是bs4
bs4的使用:1.導入模塊:from bs4 import beautifulsoup2.選擇解析器解析指定內容:
soup=beautifulsoup(解析內容,解析器)
常用解析器:html.parser,lxml,xml,html5lib
有時候需要安裝安裝解析器:比如pip3 install lxml
BeautifulSoup默認支持Python的標準HTML解析庫,但是它也支持一些第三方的解析庫:
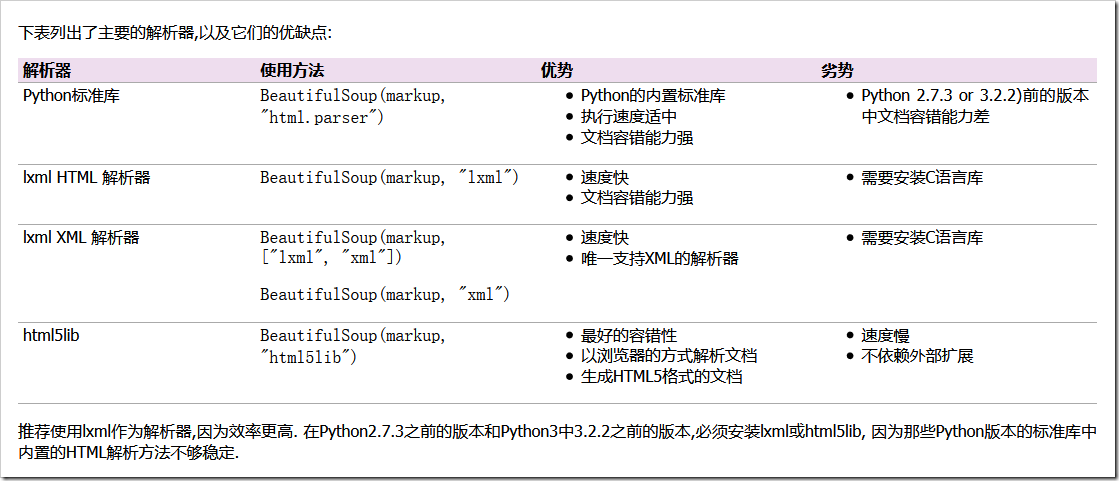
Beautiful Soup為不同的解析器提供了相同的接口,但解析器本身時有區別的.同一篇文檔被不同的解析器解析后可能會生成不同結構的樹型文檔.區別最大的是HTML解析器和XML解析器,看下面片段被解析成HTML結構:
BeautifulSoup('<a><b /></a>')# <html><head></head><body><a><b></b></a></body></html>
因為空標簽<b />不符合HTML標準,所以解析器把它解析成<b></b>
同樣的文檔使用XML解析如下(解析XML需要安裝lxml庫).注意,空標簽<b />依然被保留,并且文檔前添加了XML頭,而不是被包含在<html>標簽內:
BeautifulSoup('<a><b /></a>', 'xml')# <?xml version='1.0' encoding='utf-8'?># <a><b/></a>
HTML解析器之間也有區別,如果被解析的HTML文檔是標準格式,那么解析器之間沒有任何差別,只是解析速度不同,結果都會返回正確的文檔樹.
但是如果被解析文檔不是標準格式,那么不同的解析器返回結果可能不同.下面例子中,使用lxml解析錯誤格式的文檔,結果</p>標簽被直接忽略掉了:
BeautifulSoup('<a></p>', 'lxml')# <html><body><a></a></body></html>
使用html5lib庫解析相同文檔會得到不同的結果:
BeautifulSoup('<a></p>', 'html5lib')# <html><head></head><body><a><p></p></a></body></html>
html5lib庫沒有忽略掉</p>標簽,而是自動補全了標簽,還給文檔樹添加了<head>標簽.
使用pyhton內置庫解析結果如下:
BeautifulSoup('<a></p>', 'html.parser')# <a></a>
與lxml [7] 庫類似的,Python內置庫忽略掉了</p>標簽,與html5lib庫不同的是標準庫沒有嘗試創建符合標準的文檔格式或將文檔片段包含在<body>標簽內,與lxml不同的是標準庫甚至連<html>標簽都沒有嘗試去添加.
因為文檔片段“<a></p>”是錯誤格式,所以以上解析方式都能算作”正確”,html5lib庫使用的是HTML5的部分標準,所以最接近”正確”.不過所有解析器的結構都能夠被認為是”正常”的.
不同的解析器可能影響代碼執行結果,如果在分發給別人的代碼中使用了 BeautifulSoup ,那么最好注明使用了哪種解析器,以減少不必要的麻煩.
3.操作【約定soup是beautifulsoup(解析內容,解析器)返回的解析對象】: 使用標簽名查找 使用標簽名來獲取結點: soup.標簽名 使用標簽名來獲取結點標簽名【這個重點是name,主要用于非標簽名式篩選時,獲取結果的標簽名】: soup.標簽.name 使用標簽名來獲取結點屬性: soup.標簽.attrs【獲取全部屬性】 soup.標簽.attrs[屬性名]【獲取指定屬性】 soup.標簽[屬性名]【獲取指定屬性】 soup.標簽.get(屬性名) 使用標簽名來獲取結點的文本內容: soup.標簽.text soup.標簽.string soup.標簽.get_text()補充1:上面的篩選方式可以使用嵌套:
print(soup.p.a)#p標簽下的a標簽
補充2:以上的name,text,string,attrs等方法都可以使用在當結果是一個bs4.element.Tag對象的時候: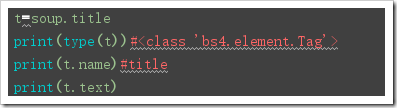
from bs4 import BeautifulSouphtml = '''<html ><head> <meta charset='UTF-8'> <title>this is a title</title></head><body><p class='news'>123</p><p id='i1'>456</p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a></body></html>'''soup = BeautifulSoup(html,’lxml’)print('獲取結點'.center(50,’-’))print(soup.head)#獲取head標簽print(soup.p)#返回第一個p標簽#獲取結點名print('獲取結點名'.center(50,’-’))print(soup.head.name)print(soup.find(id=’i1’).name)#獲取文本內容print('獲取文本內容'.center(50,’-’))print(soup.title.string)#返回title的內容print(soup.title.text)#返回title的內容print(soup.title.get_text())#獲取屬性print('-----獲取屬性-----')print(soup.p.attrs)#以字典形式返回標簽的內容print(soup.p.attrs[’class’])#以列表形式返回標簽的值print(soup.p[’class’])#以列表形式返回標簽的值print(soup.p.get(’class’))#############t=soup.titleprint(type(t))#<class ’bs4.element.Tag’>print(t.name)#titleprint(t.text)#嵌套選擇:print(soup.head.title.string) 獲取子結點【直接獲取也會獲取到’n’,會認為’n’也是一個標簽】: soup.標簽.contents【返回值是一個列表】 soup.標簽.children【返回值是一個可迭代對象,獲取實際子結點需要迭代】  獲取子孫結點: soup.標簽.descendants【返回值也是一個可迭代對象,實際子結點需要迭代】 獲取父結點: soup.標簽.parent 獲取祖先結點[父結點,祖父結點,曾祖父結點…]: soup.標簽.parents【】 獲取兄弟結點: soup.next_sibling【獲取后面的一個兄弟結點】 soup.next_siblings【獲取后面所有的兄弟結點】【返回值是一個可迭代對象】 soup.previous_sibling【獲取前一兄弟結點】 soup.previous_siblings【獲取前面所有的兄弟結點】【返回值是一個可迭代對象】
獲取子孫結點: soup.標簽.descendants【返回值也是一個可迭代對象,實際子結點需要迭代】 獲取父結點: soup.標簽.parent 獲取祖先結點[父結點,祖父結點,曾祖父結點…]: soup.標簽.parents【】 獲取兄弟結點: soup.next_sibling【獲取后面的一個兄弟結點】 soup.next_siblings【獲取后面所有的兄弟結點】【返回值是一個可迭代對象】 soup.previous_sibling【獲取前一兄弟結點】 soup.previous_siblings【獲取前面所有的兄弟結點】【返回值是一個可迭代對象】
補充3:與補充2一樣,上面的函數都可以使用在當結果是一個bs4.element.Tag對象的時候。
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a >78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span>aspan</span></body></html>'''soup = BeautifulSoup(html, ’lxml’)#獲取子結點print('獲取子結點'.center(50,’-’))print(soup.p.contents)print('n')c=soup.p.children#返回的是一個可迭代對象for i,child in enumerate(c): print(i,child)print('獲取子孫結點'.center(50,’-’))print(soup.p.descendants)c2=soup.p.descendantsfor i,child in enumerate(c2): print(i,child)print('獲取父結點'.center(50,’-’))c3=soup.title.parentprint(c3)print('獲取父,祖先結點'.center(50,’-’))c4=soup.title.parentsprint(c4)for i,child in enumerate(c4): print(i,child)print('獲取兄弟結點'.center(50,’-’))print(soup.p.next_sibling)print(soup.p.previous_sibling)for i,child in enumerate(soup.p.next_siblings): print(i,child,end=’t’)for i,child in enumerate(soup.p.previous_siblings): print(i,child,end=’t’) 使用findfind_all方式: find( name , attrs , recursive , text , **kwargs )【根據參數來找出對應的標簽,但只返回第一個符合條件的結果】
find_all( name , attrs , recursive , text , **kwargs ):【根據參數來找出對應的標簽,但只返回所有符合條件的結果】
篩選條件參數介紹:
name:為標簽名,根據標簽名來篩選標簽
attrs:為屬性,,根據屬性鍵值對來篩選標簽,賦值方式可以為:屬性名=值,attrs={屬性名:值}【但由于class是python關鍵字,需要使用class_】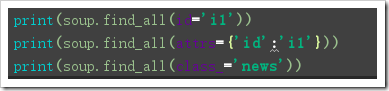
text:為文本內容,根據指定文本內容來篩選出標簽,【單獨使用text作為篩選條件,只會返回text,所以一般與其他條件配合使用】
recursive:指定篩選是否遞歸,當為False時,不會在子結點的后代結點中查找,只會查找子結點
獲取到結點后的結果是一個bs4.element.Tag對象,所以對于獲取屬性、文本內容、標簽名等操作可以參考前面“使用標簽篩選結果”時涉及的方法
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a id=’i2’>78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span>aspan</span></body></html>'''soup = BeautifulSoup(html, ’lxml’)print('---------------------')print(soup.find_all(’a’),end=’nn’)print(soup.find_all(’a’)[0])print(soup.find_all(attrs={’id’:’i1’}),end=’nn’)print(soup.find_all(class_=’news’),end=’nn’)print(soup.find_all(’a’,text=’123456’))#print(soup.find_all(id=’i2’,recursive=False),end=’nn’)#a=soup.find_all(’a’)print(a[0].name)print(a[0].text)print(a[0].attrs) 使用select篩選【select使用CSS選擇規則】: soup.select(‘標簽名’),代表根據標簽來篩選出指定標簽 CSS中#xxx代表篩選id,soup.select(‘#xxx’)代表根據id篩選出指定標簽,返回值是一個列表 CSS中.###代表篩選class,soup.select(’.xxx’)代表根據class篩選出指定標簽,返回值是一個列表 嵌套select: soup.select(“#xxx .xxxx”),如(“#id2 .news”)就是id=”id2”標簽下class=”news的標簽,返回值是一個列表 獲取到結點后的結果是一個bs4.element.Tag對象,所以對于獲取屬性、文本內容、標簽名等操作可以參考前面“使用標簽篩選結果”時涉及的方法
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a id=’i2’>78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span id=’i4’>aspan</span></body></html>'''soup = BeautifulSoup(html, ’lxml’)sp1=soup.select(’span’)#返回結果是一個列表,列表的元素是bs4元素標簽對象print(soup.select('#i2'),end=’nn’)print(soup.select('.news'),end=’nn’)print(soup.select('.news #i2'),end=’nn’)print(type(sp1),type(sp1[0]))print(sp1[0].name)#列表里面的元素才是bs4元素標簽對象print(sp1[0].attrs)print(sp1[0][’class’])
補充4:
對于代碼不齊全的情況下,可以使用soup.prettify()來自動補全,一般情況下建議使用,以避免代碼不齊。
from bs4 import BeautifulSouphtml = '''<html lang='en'><head> <meta charset='UTF-8'> <title>Title</title></head><body><p class='news'><a >123456</a> <a id=’i2’>78910</a></p><p id='i1'></p><a rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' rel='external nofollow' >advertisements</a><span id=’i4’>aspan</html>'''soup = BeautifulSoup(html, ’lxml’)c=soup.prettify()#上述html字符串中末尾缺少</span> 和 </body>print(c)
如果想要獲得更詳細的介紹,可以參考官方文檔,令人高興的是,有了比較簡易的中文版:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
更多關于Python相關內容可查看本站專題:《Python Socket編程技巧總結》、《Python正則表達式用法總結》、《Python數據結構與算法教程》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》、《Python入門與進階經典教程》及《Python文件與目錄操作技巧匯總》
希望本文所述對大家Python程序設計有所幫助。
相關文章:

 網公網安備
網公網安備