使用python svm實現(xiàn)直接可用的手寫數(shù)字識別
最近在做個圍棋識別的項目,需要識別下面的數(shù)字,如下圖:
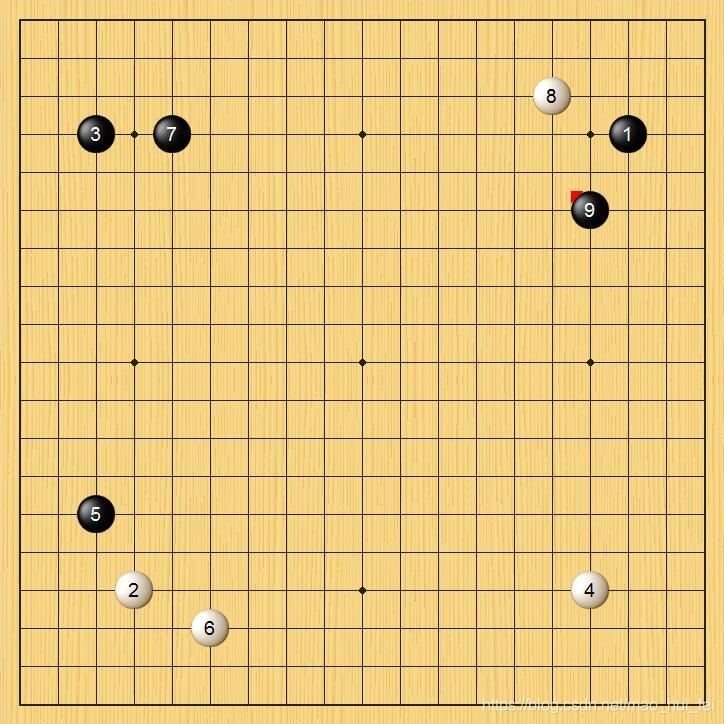
我發(fā)現(xiàn)現(xiàn)在網(wǎng)上很多代碼是良莠不齊,…真是一言難盡,于是記錄一下,能夠運行成功并識別成功的一個源碼。
1、訓練1.1、訓練數(shù)據(jù)集下載——已轉化成csv文件下載地址
1.2 、訓練源碼train.py
import pandas as pdfrom sklearn.decomposition import PCAfrom sklearn import svmfrom sklearn.externals import joblibimport timeif __name__ =='__main__': train_num = 5000 test_num = 7000 data = pd.read_csv(’train.csv’) train_data = data.values[0:train_num,1:] train_label = data.values[0:train_num,0] test_data = data.values[train_num:test_num,1:] test_label = data.values[train_num:test_num,0] t = time.time() #PCA降維 pca = PCA(n_components=0.8, whiten=True) print(’start pca...’) train_x = pca.fit_transform(train_data) test_x = pca.transform(test_data) print(train_x.shape) # svm訓練 print(’start svc...’) svc = svm.SVC(kernel = ’rbf’, C = 10) svc.fit(train_x,train_label) pre = svc.predict(test_x) #保存模型 joblib.dump(svc, ’model.m’) joblib.dump(pca, ’pca.m’) # 計算準確率 score = svc.score(test_x, test_label) print(u’準確率:%f,花費時間:%.2fs’ % (score, time.time() - t))2、預測單張圖片2.1、待預測圖像

from sklearn.externals import joblibimport cv2if __name__ =='__main__': img = cv2.imread('img_temp.jpg', 0) #test = img.reshape(1,1444) Tp_x = 10 Tp_y = 10 Tp_width = 20 Tp_height = 20 img_temp = img[Tp_y:Tp_y + Tp_height, Tp_x:Tp_x + Tp_width] # 參數(shù)含義分別是:y、y+h、x、x+w cv2.namedWindow('src', 0) cv2.imshow('src', img_temp) cv2.waitKey(1000) [height, width] = img_temp.shape print(width, height) res_img = cv2.resize(img_temp, (28, 28)) test = res_img.reshape(1, 784) #加載模型 svc = joblib.load('model.m') pca = joblib.load('pca.m') # svm print(’start pca...’) test_x = pca.transform(test) print(test_x.shape) pre = svc.predict(test_x) print(pre[0])2.3、預測結果
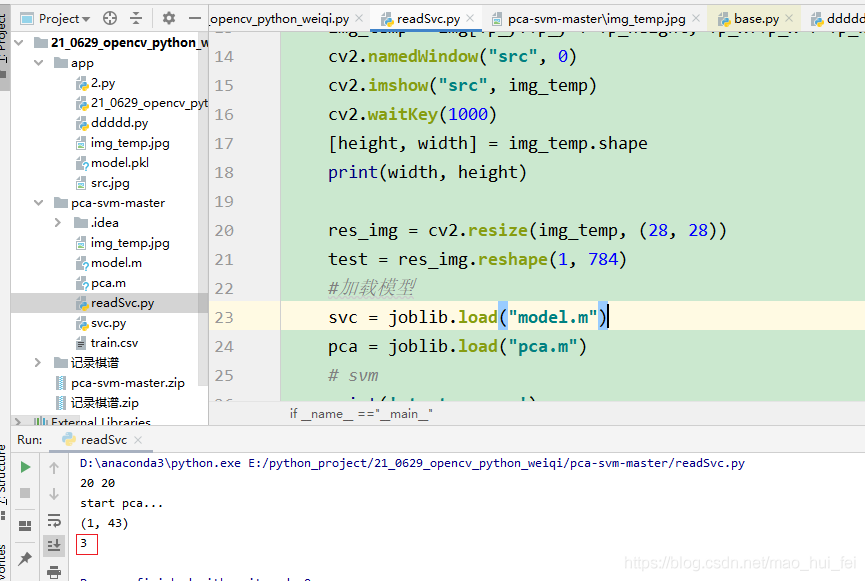
到此這篇關于使用python svm實現(xiàn)直接可用的手寫數(shù)字識別的文章就介紹到這了,更多相關python svm 手寫數(shù)字識別內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持好吧啦網(wǎng)!
相關文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備