(手寫)PCA原理及其Python實(shí)現(xiàn)圖文詳解
為什么需要降維呢?
因?yàn)閿?shù)據(jù)個數(shù) N 和每個數(shù)據(jù)的維度 p 不滿足 N >> p,造成了模型結(jié)果的“過擬合”。有兩種方法解決上述問題:
增加N;減小p。
這里我們講解的 PCA 屬于方法2。
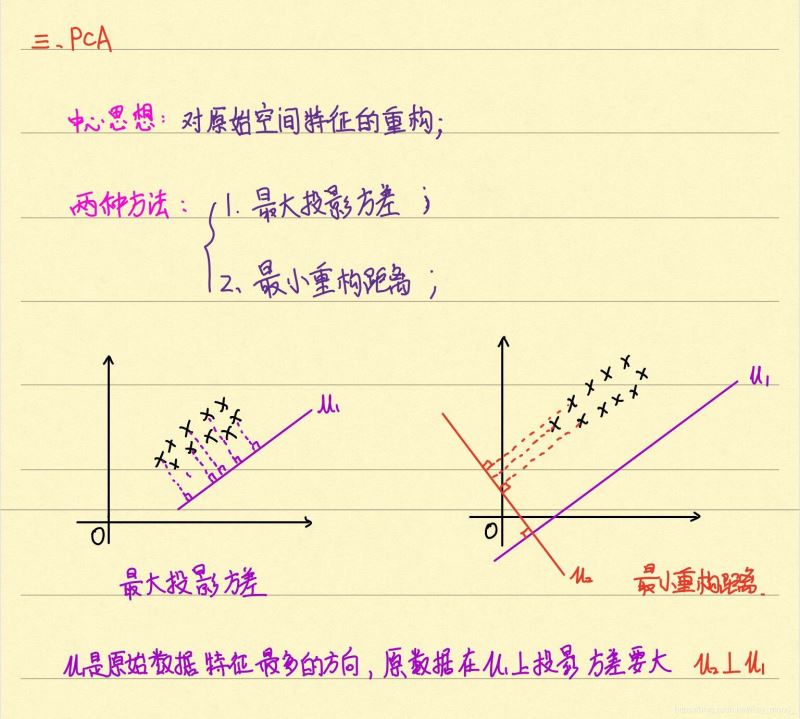
2、樣本均值和樣本方差矩陣




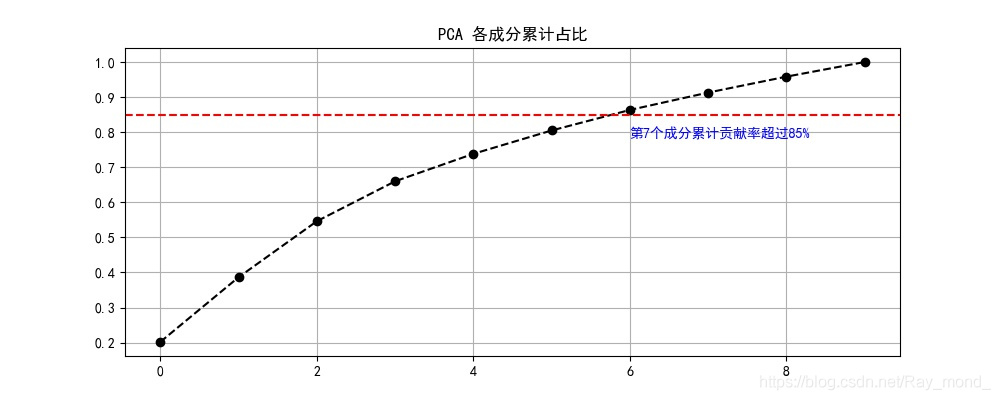
''' -*- coding: utf-8 -*- @ Time : 2021/8/15 22:19 @ Author : Raymond @ Email : [email protected] @ Editor : Pycharm'''from sklearn.datasets import load_digitsfrom sklearn.decomposition import PCAimport pandas as pdimport matplotlib.pyplot as pltdigits = load_digits()print(digits.keys())print('數(shù)據(jù)的形狀為: {}'.format(digits[’data’].shape))# 構(gòu)建模型 - 降到10 dpca = PCA(n_components=10)pca.fit(digits.data)projected=pca.fit_transform(digits.data)print(’降維后主成分的方差值為:’,pca.explained_variance_)print(’降維后主成分的方差值占總方差的比例為:’,pca.explained_variance_ratio_)print(’降維后最大方差的成分為:’,pca.components_)print(’降維后主成分的個數(shù)為:’,pca.n_components_)print(’original shape:’,digits.data.shape)print(’transformed shape:’,projected.shape)s = pca.explained_variance_c_s = pd.DataFrame({’b’: s,’b_sum’: s.cumsum() / s.sum()})c_s[’b_sum’].plot(style= ’--ko’,figsize= (10, 4))plt.rcParams[’font.sans-serif’] = [’SimHei’] # 指定默認(rèn)字體plt.rcParams[’axes.unicode_minus’] = False # 解決保存圖像是負(fù)號’-’顯示為方塊的問題plt.axhline(0.85, color= ’r’,linestyle= ’--’)plt.text(6, c_s[’b_sum’].iloc[6]-0.08, ’第7個成分累計貢獻(xiàn)率超過85%’, color=’b’)plt.title(’PCA 各成分累計占比’)plt.grid()plt.savefig(’./PCA.jpg’)plt.show()
結(jié)果展示:
本篇文章就到這里了,希望能給你帶來幫助,也希望您能夠多多關(guān)注好吧啦網(wǎng)的更多內(nèi)容!
相關(guān)文章:
1. ASP實(shí)現(xiàn)加法驗(yàn)證碼2. 無線標(biāo)記語言(WML)基礎(chǔ)之WMLScript 基礎(chǔ)第1/2頁3. ASP刪除img標(biāo)簽的style屬性只保留src的正則函數(shù)4. PHP循環(huán)與分支知識點(diǎn)梳理5. ASP基礎(chǔ)入門第三篇(ASP腳本基礎(chǔ))6. 利用CSS3新特性創(chuàng)建透明邊框三角7. 解析原生JS getComputedStyle8. css代碼優(yōu)化的12個技巧9. 前端從瀏覽器的渲染到性能優(yōu)化10. 讀大數(shù)據(jù)量的XML文件的讀取問題

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備