Python爬取數據并實現可視化代碼解析
這次主要是爬了京東上一雙鞋的相關評論:將數據保存到excel中并可視化展示相應的信息
主要的python代碼如下:
文件1
#將excel中的數據進行讀取分析import openpyxlimport matplotlib.pyplot as pit #數據統計用的wk=openpyxl.load_workbook(’銷售數據.xlsx’)sheet=wk.active #獲取活動表#獲取最大行數和最大列數rows=sheet.max_rowcols=sheet.max_columnlst=[] #用于存儲鞋子碼數for i in range (2,rows+1): size=sheet.cell(i,3).value lst.append(size)#以上已經將excel中的數據讀取完畢#一下操作就你行統計不同碼數的數量’’’python中有一個數據結構叫做字典,使用鞋碼做key,使用銷售數量做value’’’dic_size={}for item in lst: dic_size[item]=0for item in lst: for size in dic_size: #遍歷字典 if item==size: dic_size[size]+=1 breakfor item in dic_size: print(item,dic_size[item])#弄成百分比的形式lst_total=[]for item in dic_size: lst_total.append([item,dic_size[item],dic_size[item]/160*1.0])#接下來進行數據的可視化(進行畫餅操作)labels=[item[0] +’碼’for item in lst_total] #使用列表生成式,得到餅圖的標簽fraces=[item[2] for item in lst_total] #餅圖中的數據源pit.rcParams[’font.family’]=[’SimHei’] #單獨的表格亂碼的處理方式pit.pie(x=fraces,labels=labels,autopct=’%1.1f%%’)#pit.show()進行結果的圖片的展示pit.savefig(’圖.jpg’)
文件2
#所涉及到的是requests和openpyxl數據的存儲和數據的清洗以及統計然后就是matplotlib進行數據的可視化#靜態數據點擊element中點擊發現在html中,服務器已經渲染好的內容,直接發給瀏覽器,瀏覽器解釋執行,#動態數據:如果點擊下一頁。我們的地址欄(加后綴但是前面的地址欄沒變也算)(也可以點擊2和3頁)沒有發生任何變化說明是動態數據,說明我們的數據是后來被渲染到html中的。他的數據根本不在html中的。#動態查看network然后用的url是network里面的headers#安裝第三方模塊輸入cmd之后pip install 加名字例如requestsimport requestsimport reimport timeimport jsonimport openpyxl #用于操作 excel文件的headers = {’user-agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36’}#創建頭部信息def get_comments(productId,page): url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page) resp = requests.get(url, headers=headers) s=resp.text.replace(’fetchJSON_comment98(’,’’)#進行替換操作。獲取到所需要的相應的json,也就是去掉前后沒用的東西 s=s.replace(’);’,’’) json_data=json.loads(s)#進行數據json轉換 return json_data#獲取最大頁數def get_max_page(productId): dis_data=get_comments(productId,0)#調用剛才寫的函數進行向服務器的訪問請求,獲取字典數據 return dis_data[’maxPage’]#獲取他的最大頁數。每一頁都有最大頁數#進行數據提取def get_info(productId): max_page=get_max_page(productId) lst=[]#用于存儲提取到的商品數據 for page in range(1,max_page+1): #獲取沒頁的商品評論 comments=get_comments(productId,page) comm_list=comments[’comments’]#根據comnents獲取到評論的列表(每頁有10條評論) #遍歷評論列表,獲取其中的相應的數據 for item in comm_list: #每條評論分別是一字典。在繼續通過key來獲取值 content=item[’content’] color=item[’productColor’] size=item[’productSize’] lst.append([content,color,size])#將每條評論添加到列表當中 time.sleep(3)#防止被京東封ip進行一個時間延遲。防止訪問次數太頻繁 save(lst)def save(lst): #把爬取到的數據進行存儲,保存到excel中 wk=openpyxl.Workbook()#用于創建工作簿對象 sheet=wk.active #獲取活動表(一個工作簿有三個表) #遍歷列表將數據添加到excel中。列表中的一條數據在表中是一行 biaotou=’評論’,’顏色’,’大小’ sheet.append(biaotou) for item in lst: sheet.append(item) #將excel保存到磁盤上 wk.save(’銷售數據.xlsx’)if __name__==’__main__’: productId=’66749071789’ get_info(productId) print('ok')
實現的效果如下:
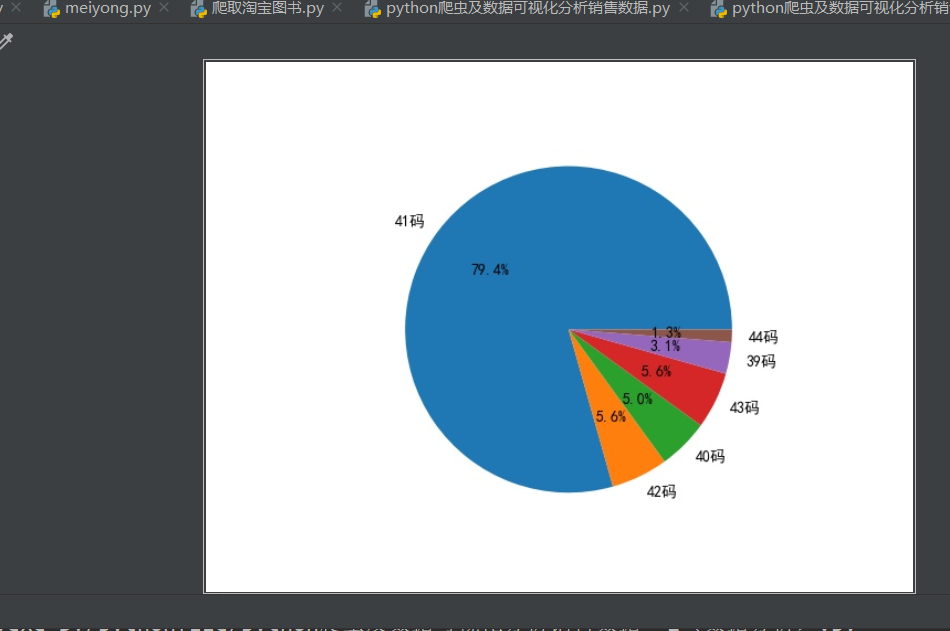
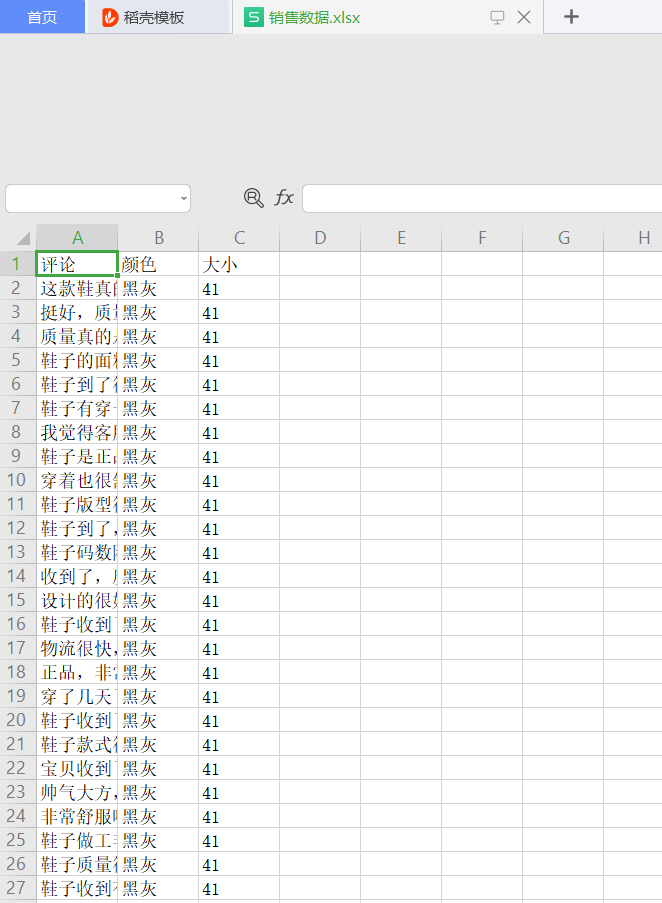
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:
 網公網安備
網公網安備