Python 通過爬蟲實現GitHub網頁的模擬登錄的示例代碼
1. 實例描述
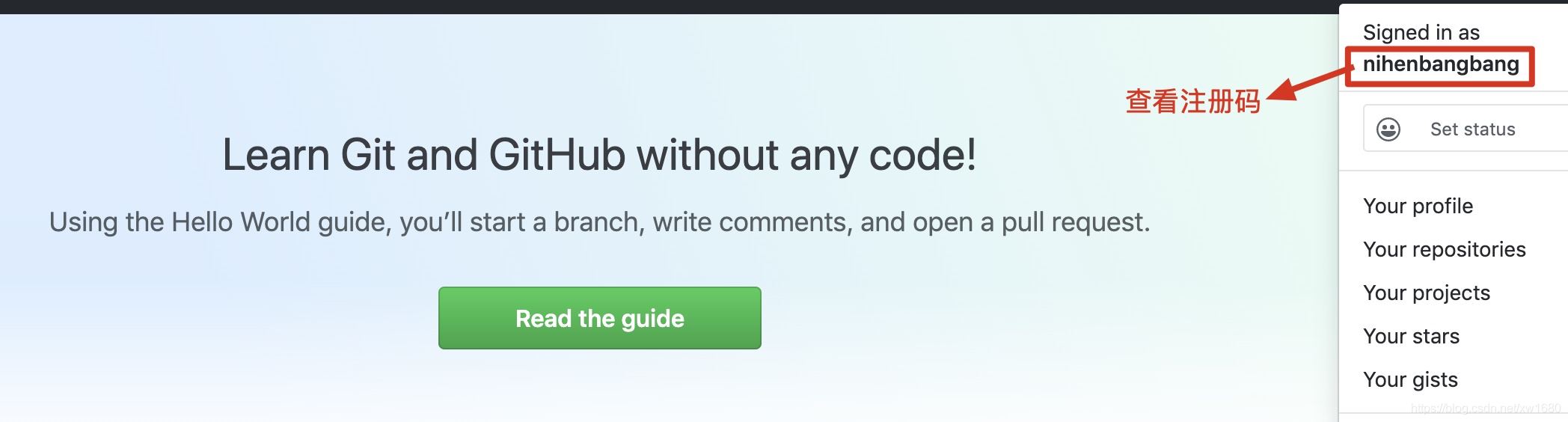
通過爬蟲獲取網頁的信息時,有時需要登錄網頁后才可以獲取網頁中的可用數據,例如獲取 GitHub 網頁中的注冊號碼時,就需要先登錄賬號才能在登錄后的頁面中看到該信息,如下圖所示。那么該如何實現模擬登錄的功能呢?本文實現將通過爬蟲實現 GitHub 網頁的模擬登錄。
2. 代碼實現
在實現 GitHub 網頁的模擬登錄時,首先需要查看提交登錄請求時都要哪些請求參數,然后獲取登錄請求的所有參數,再發送登錄請求。如果登錄成功的情況下獲取頁面中的注冊號碼信息即可。具體步驟如下:
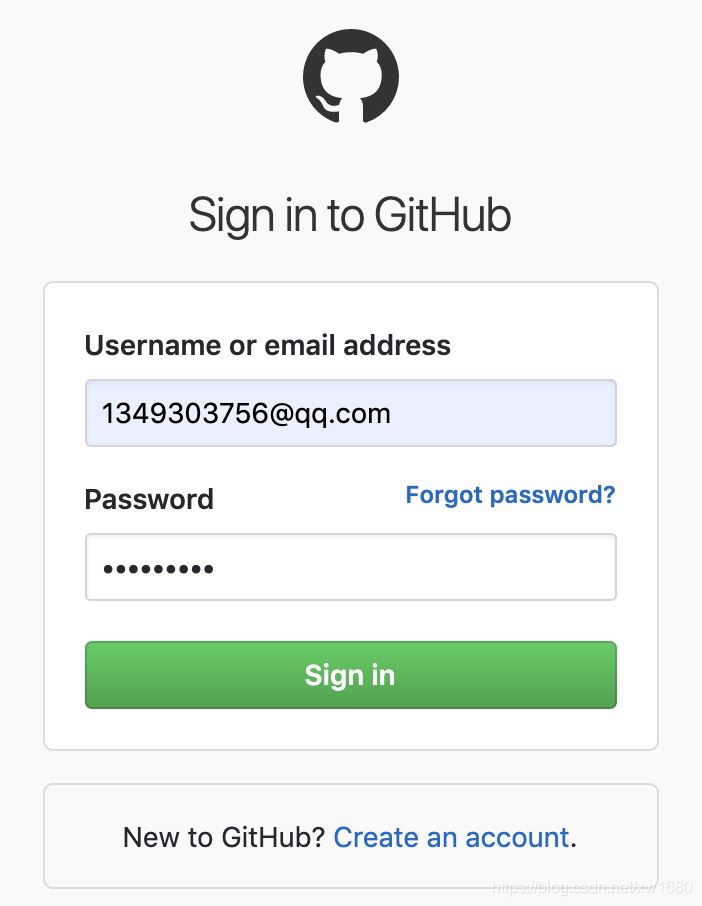
(1) 點擊 此處 打開 GitHub 的登錄頁面,然后輸入賬號與密碼,如下圖所示。
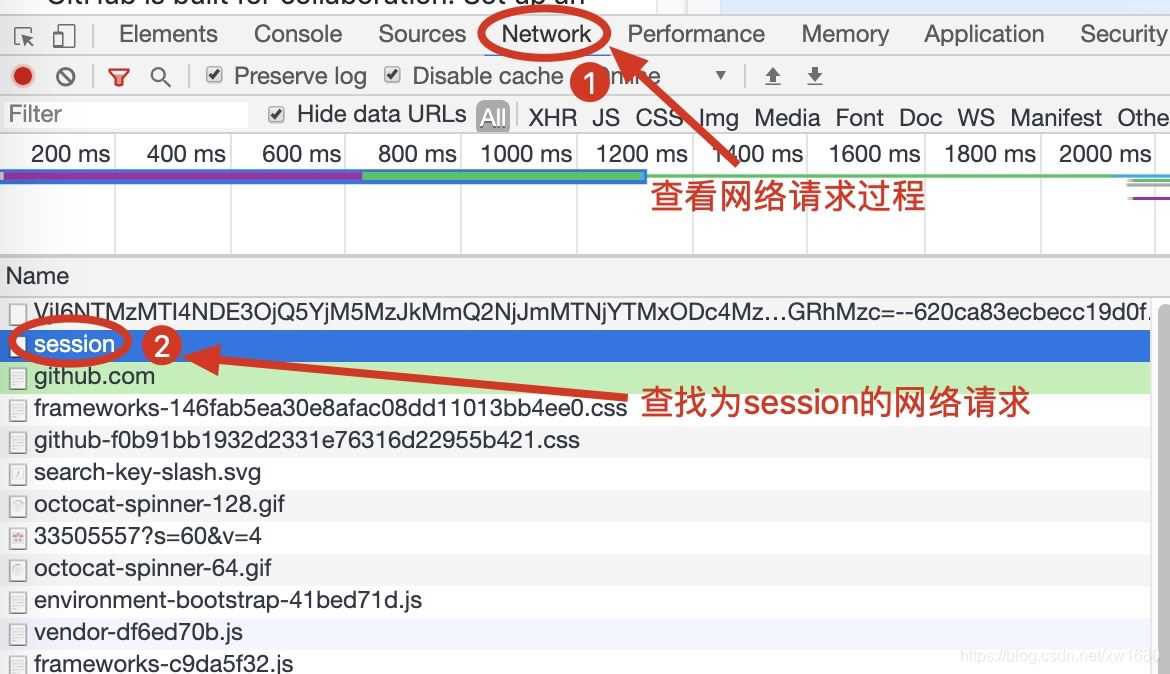
(2) 用 F12 或者 鼠標右鍵單擊網頁選擇 檢查 打開瀏覽器的開發者工具,選擇獲取網絡請求過程,然后單擊登錄頁面中的 Sign in 按鈕,此時開發者工具中將顯示 GitHub 網頁的登錄請求過程,重點查找名稱為 session 的網絡請求。如下圖所示。
(3) 單擊名稱為 session 的網絡請求,然后在 Headers 請求信息中主要查看 Request Headers與 Form Data 中的各種信息,其中紅框內為重要參數與數據。如下圖所示。

說明:Host 為主頁面地址,Referer 為當前請求的來源地址。User-Agent 為瀏覽器的頭部信息。Form Data 中的所有信息都是登錄請求的所用參數,其中動態參數為重要參數,authenticity_token 為加密字符串,login 為登錄的賬號,password 為密碼,其它參數為靜態參數。由于動態參數只有 authenticity_token、login 以及password ,而用戶名與密碼只需要將動態字符串填寫對應的位置即可,所以接下來需要獲取 authenticity_token 參數所對應的加密字符串。
(4) 在瀏覽器中退出所登錄的 GitHub 賬號,返回 GitHub 的登錄頁面,打開瀏覽器開發者工具,查看網頁的 html 代碼,然后在代碼中搜索 authenticity_token 關鍵詞,標簽內 value 所對應的值為 authenticity_token 參數的加密字符串。如下圖所示。

(5) 實現爬蟲代碼,首先導入所需模塊,然后創建頭部信息,再通過 Session 會話對象發送網絡請求獲取 authenticity_token 信息,最后通過所有的登陸請求參數實現 GitHub 網頁的登陸請求并提取注冊號碼。具體代碼如下:
# -*- coding: utf-8 -*-# @Time : 2020/5/10 23:25# @Author : 我就是任性-Amo# @FileName: 77.通過爬蟲實現GitHub網頁的模擬登錄.py# @Software: PyCharm# @Blog :https://blog.csdn.net/xw1680import requests # 導入網絡請求模塊from lxml import etree # 導入數據解析模塊 都是第三方模塊需要安裝 # pip install requests/lxml如果太慢 可以加上鏡像服務器 或者在Pycharm中使用圖形化界面進行安裝class GitHubLogin(object): def __init__(self, username, password): # 構造頭部信息 self.headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', 'Host': 'github.com', 'Referer': 'https://github.com/login' } self.login_url = 'https://github.com/login' # 登錄頁面地址 self.post_url = 'https://github.com/session' # 實現登錄的請求地址 self.session = requests.Session() # 創建Session會話對象 self.user_name = username # 用戶名 self.password = password # 密碼 # 獲取authenticity_token信息 def get_token(self): # 發送登錄頁面的網絡請求 response = self.session.get(self.login_url, headers=self.headers) if response.status_code == 200: # 判斷請求是否成功 html = etree.HTML(response.text) # 解析html # 提取authenticity_token信息 token = html.xpath('//div[@id=’login’]/form/input[1]/@value')[0] # print(token) 測試是否能夠獲取到token return token # 返回信息 # 實現登錄 def login(self): # 請求參數 post_data = { 'commit': 'Sign in', 'authenticity_token': self.get_token(), 'login': self.user_name, 'password': self.password, 'webauthn - support': 'supported' } # 發送登錄請求 response = self.session.post(self.post_url, headers=self.headers, data=post_data) if response.status_code == 200: # 判斷請求是否成功 html = etree.HTML(response.text) # 解析html # 獲取注冊號碼 register_number = html.xpath('//div[contains(@class,’Header-item’)][last()]//strong')[0] print(f'注冊號碼為: {register_number.text}') else: print('登錄失敗')if __name__ == ’__main__’: user_name = input('請輸入您的用戶名:') # 獲取輸入的用戶名 password = input('請輸入您的密碼:') # 獲取輸入的密碼 login = GitHubLogin(user_name, password) # 創建登錄類對象并傳遞輸入的用戶名與密碼 login.login()
執行以上代碼,輸入用戶名與密碼,即可顯示獲取的注冊號碼。如下圖所示:

到此這篇關于Python 通過爬蟲實現GitHub網頁的模擬登錄的示例代碼的文章就介紹到這了,更多相關Python GitHub模擬登錄內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備