Python使用正則表達式實現爬蟲數據抽取
首先,大家來看一個例子。一個文本文件里面存儲了一些市場職位信息,格式如下所示:
Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員測試開發工程師(C++/python) 上海墨?數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人Python高級開發工程師 上海行動教育科技股份有限公司上海-閔行區2.8萬/月02-18剩余255人python開發工程師 上海優似騰軟件開發有限公司上海-浦東新區2.5萬/每月02-18滿員
現在,我們需要編寫一個程序,從這些文本里面抓取所有職位的薪資。獲取結果如下所示:
22.51.31.12.82.5
怎么做?大家可以先自己思考一下。這是典型的字符串處理。分析這里面的規律,可以發現,薪資的數字后面都有關鍵字萬/月或者萬/每月。根據我們學過的知識,我們不難寫出下面的代碼:
html_str = ''' Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員 測試開發工程師(C++/python) 上海墨?數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員 Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人 測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人 Python高級開發工程師 上海行動教育科技股份有限公司上海-閔行區2.8萬/月02-18剩余255人 python開發工程師 上海優似騰軟件開發有限公司上海-浦東新區2.5萬/每月02-18滿員'''# 將字符串html_str中每一行的數據提取出來存入到一個列表中position_info_list = html_str.splitlines()for position_info in position_info_list: # 遍歷 if position_info: # 判斷是否有數據 # 查找萬/月或者是萬/每月的索引 idx = position_info.find('萬/月') if position_info.find('萬/月') != -1 else position_info.find('萬/每月') end_pos = idx # 記錄結束位置 if idx == -1: continue # 上面兩種都沒找到 find_start = idx - 1 # 記錄萬字前的位置 while position_info[find_start].isdigit() or position_info[find_start] == '.': find_start -= 1 start_pos = find_start + 1 # 開始位置 print(position_info[start_pos: end_pos]) # 切片獲取薪資
運行一下,發現完全可以。如圖所示:
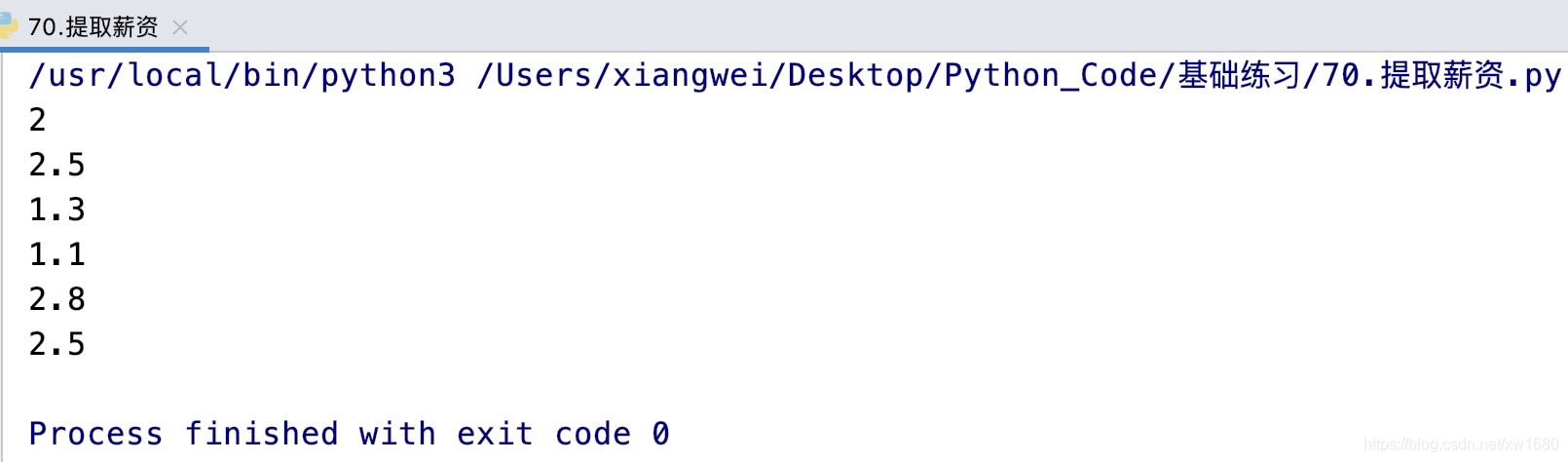
在你高興完之后,我們再看看寫的代碼。怎么樣?太麻煩了,是不是。為了從每行獲取薪資對應的數字,我們可是寫了不少行代碼。這種從字符串中搜索出某種特征的子串有沒有更簡單的方法呢?解決方案就是我們今天要介紹的正則表達式。如果我們使用正則表達式,代碼可以這樣:
import rehtml_str = ''' Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員 測試開發工程師(C++/python) 上海墨?數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員 Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人 測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人 Python高級開發工程師 上海行動教育科技股份有限公司上海-閔行區2.8萬/月02-18剩余255人 python開發工程師 上海優似騰軟件開發有限公司上海-浦東新區2.5萬/每月02-18滿員'''salary_list = re.findall(r'([d.]+)萬/每?月', html_str)for salary in salary_list: print(salary)
運行一下看看,結果是一樣的。但是代碼卻簡單多了。從上面的例子可以看出,用正則表達式關鍵的地方在于如何寫出正確的表達式語法。正則表達式非常強大,語法非常復雜,如果你英文閱讀能力還可以,那太好了,點擊這里,參考Python官方文檔里面的描述 。具體的使用細節包括語法都在里面。本文會給大家介紹一些常見的正則表達式語法。
2. 什么是正則表達式?在處理字符串時,經常會有查找符合某些復雜規則的字符串的需求。正則表達式就是用于描述這些規則的工具。換句話說,正則表達式就是記錄文本規則的代碼。對于接觸過DOS/終端的用戶來說,如果想匹配當前文件夾下所有的文本文件,可以輸入dir *.txt/ls *.txt命令,按<Enter>鍵后,所有.txt文件將會被列出來。這里的*.txt即可理解為一個簡單的正則表達式。

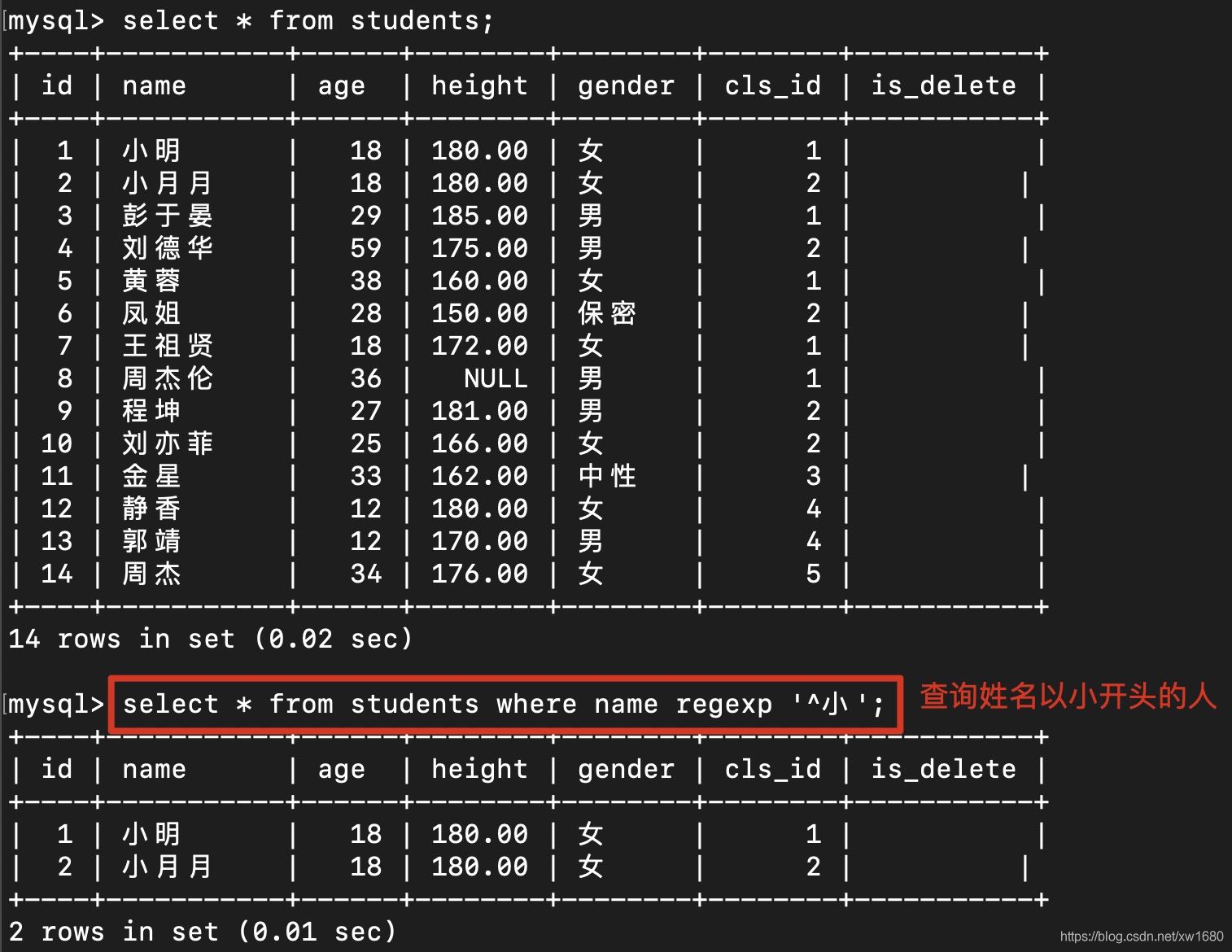
在數據庫中使用正則表達式,如圖所示:
Python提供了re模塊,用于實現正則表達式的操作。在實現時,可以使用re模塊提供的方法search()、 match()、findall()等進行字符串處理,也可以先使用re模塊的compile()方法將模式字符串轉換為正則表達式對象,然后再使用該正則表達式對象的相關方法來操作字符串。re模塊在使用時,需要先應用import語句引入,具體代碼如下:
import re
這里因為我們還沒有學習匹配的規則,所以先學習一下match方法,其他的方法在本文末尾講解。match()方法用于從字符串的開始處進行匹配,如果在起始位置匹配成功,則返回Match對象,否則返回None,語法格式如下:
re.match(pattern, string, [flags] )參數說明:1. pattern:表示模式字符串,由要匹配的正則表達式轉換而來。2. string:表示要匹配的字符串。3. flags:可選參數,表示標志位,用于控制匹配方式,如是否區分字母大小寫。
常用的flags如下表所示:
標志 說明 A 或ASCII 對于w、W、b、B、d、D、s和S只進行ASCII匹配(僅適用于Python 3.x) I或IGNORECASE 執行不區分字母大小寫的匹配 M或MULTILINE 將^和$用于包括整個字符串的開始和結尾的每一行(默認情況下,僅適用于整個字符串的開始和結尾處) S或DOTALL 使用(.)字符匹配所有字符,包括換行符 X或VERBOSE 忽略模式字符串中未轉義的空格和注釋
例如,匹配字符串是否以amo_開頭,不區分字母大小寫,代碼如下:

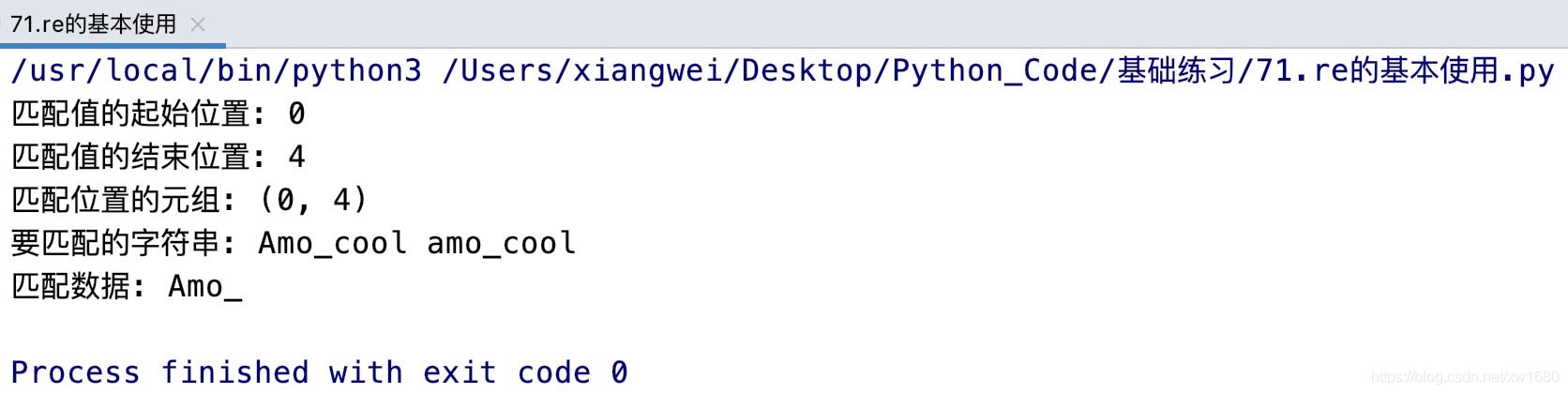
從上面的執行結果中可以看出,字符串Amo_cool是以amo_開頭,所以返回一個Match對象,而字符串外貌描述 Amo_ cool不是以amo_開頭,將返回None。這是因為match()方法從字符串的開始位置開始匹配,當第一個字母不符合條件時,則不再進行匹配,直接返回None。Match對象中包含了匹配值的位置和匹配數據。其中,要獲取匹配值的起始位置可以使用Match對象的start() 方法 要獲取匹配值的結束位置可以使用end()方法 通過span()方法可以返回匹配位置的元組 通過string屬性可以獲取要匹配的字符串。例如下面的代碼:
import repattern = r'amo_' # 模式字符串str1 = 'Amo_cool amo_cool' # 要匹配的字符串match = re.match(pattern, str1, re.I) # 匹配字符串 不區分大小寫print(f'匹配值的起始位置: {match.start()}')print(f'匹配值的結束位置: {match.end()}')print(f'匹配位置的元組: {match.span()}')print(f'要匹配的字符串: {match.string}')print(f'匹配數據: {match.group()}'
運行結果如圖所示:
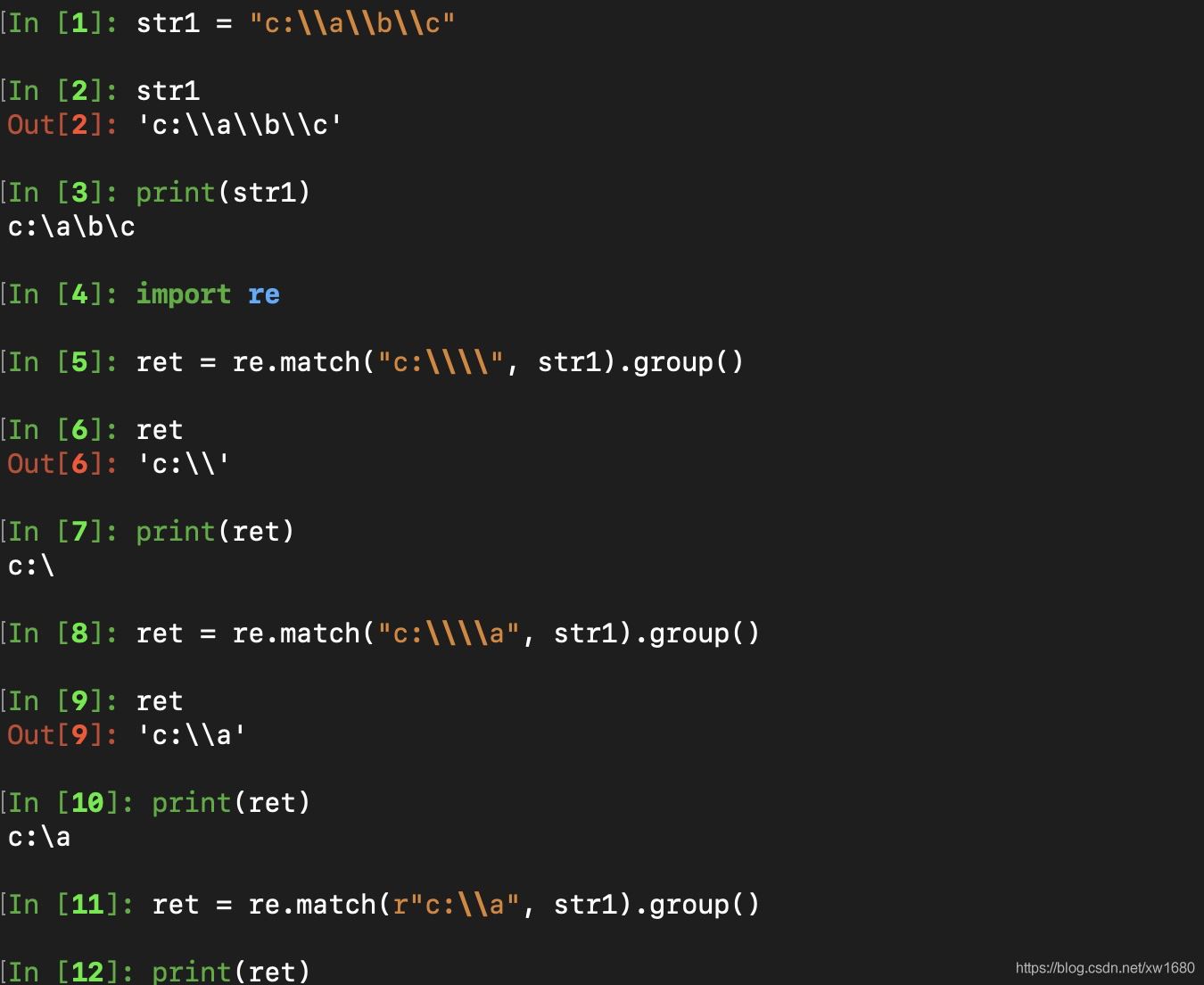
Python中字符串前面加上r表示原生字符串,與大多數編程語言相同,正則表達式里使用作為轉義字符,這就可能造成反斜杠困擾。假如你需要匹配文本中的字符,那么使用編程語言表示的正則表達式里將需要4個反斜杠:前兩個和后兩個分別用于在編程語言里轉義成反斜杠,轉換成兩個反斜杠后再在正則表達式里轉義成一個反斜杠。Python里的原生字符串很好地解決了這個問題,有了原生字符串,你再也不用擔心是不是漏寫了反斜杠,寫出來的表達式也更直觀。如圖所示:
在上一小節中,了解到通過re模塊能夠完成使用正則表達式來匹配字符串。本小節,將要講解正則表達式的單字符匹配,具體的規則,如下所示:
實例 描述 . 匹配除'n'之外的任何單個字符。要匹配包括'n'在內的任何字符,請使用'[.n]'模式。 d 匹配一個數字字符。等價于 [0-9]。 D 匹配一個非數字字符。等價于 [^0-9]。 s 匹配任何空白字符,包括空格、制表符、換頁符等等。等價于[ fnrtv]。 S 匹配任何非空白字符。等價于 [^ fnrtv]。 w 匹配包括下劃線的任何單詞字符。等價于'[A-Za-z0-9_]'。 W 匹配任何非單詞字符。等價于'[^A-Za-z0-9_]'。 […] 用來表示一組字符,單獨列出:[amk] 匹配 ‘a’,‘m’或’k’ [^…] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 ^ 匹配字符串的開頭 $ 匹配字符串的結尾
例子如下:

匹配多個字符的相關格式:
實例 描述 re* 匹配0個或多個的表達式 。 re+ 匹配1個或多個的表達式。 re? 匹配0個或1個由前面的正則表達式定義的片段,非貪婪方式。 re{n} 匹配n個前面表達式。例如,o{2}不能匹配Bob中的o,但是能匹配food中的兩個o。 re{n,} 精確匹配n個前面表達式。例如,o{2,}不能匹配Bob中的o,但能匹配foooood中的所有o。o{1,}等價于o+。o{0,}則等價于o*。 re{n,m} 匹配 n 到 m 次由前面的正則表達式定義的片段,貪婪方式
例子如下:
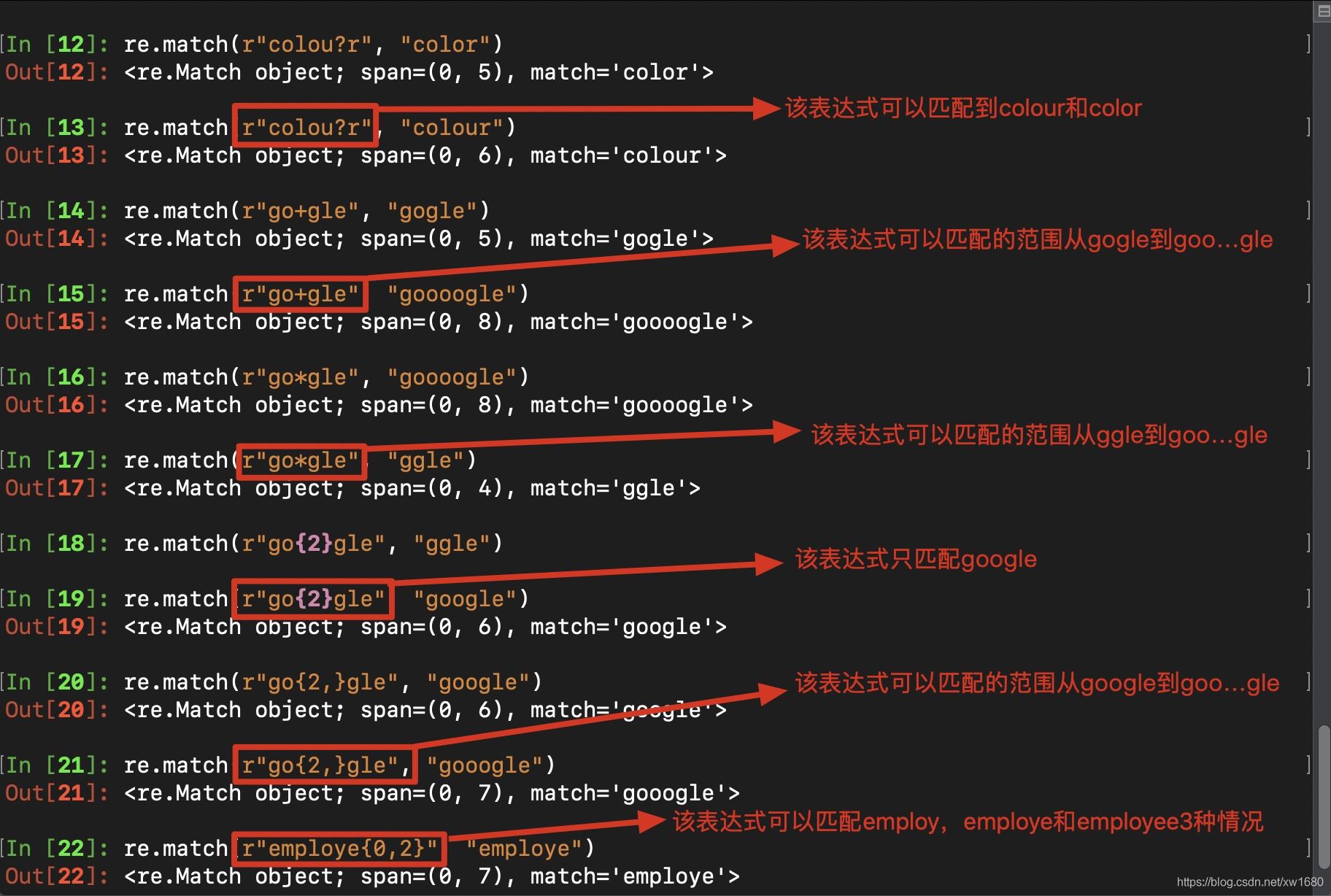
實例 描述 a|b 匹配a或b (re) 匹配括號內的表達式,也表示一個組 num 引用分組num匹配到的字符串 (?P<name>) 分組起別名 (?P=name) 引用別名為name分組匹配到的字符串
練習1:匹配出0-100之間的數字
result = re.match(r'[1-9]?d$|100', '70').group()
練習2:匹配出163、126、qq、sina郵箱要求:可使用英文小寫 數字 下劃線,下劃線不能在首尾且@符號之前有4到16位字符

result = re.match(r'^[a-z0-9][a-z0-9_]{2,14}[a-z0-9]@(163|126|qq|sina).com$', '[email protected]').group()
練習3:匹配出<html><body>amo666</body></html>
import restr1 = '<html><body>amo666</body></html>'pattern1 = r'<([a-zA-Z]*)><([a-zA-Z]*)>.*</2></1>'match_obj1 = re.match(pattern1, str1)print(match_obj1.group())pattern2 = r'<(?P<name1>[a-zA-Z]*)><(?P<name2>[a-zA-Z]*)>.*</(?P=name2)></(?P=name1)>'match_obj2 = re.match(pattern2, str1)print(match_obj2.group())
執行結果如下:
<html><body>amo666</body></html><html><body>amo666</body></html>
7. re模塊的高級用法7.1 使用search()方法進行匹配search()方法用于在整個字符串中搜索第一個匹配的值, 如果匹配成功,則返回Match對象,否則返回None,語法格式如下:
re. search(pattern, string, [flags])
參數說明:
pattern:表示模式字符串,由要匹配的正則表達式轉換而來。 string:表示要匹配的字符串。 flags:可選參數,表示標志位,用于控制匹配方式,如是否區分字母大小寫。例如,搜索第一個以amo_開頭的字符串,不區分字母大小寫,代碼如下:
import rematch_obj1 = re.search(r'amo_w+', 'Amo_SHOP amo_shop', re.I)print(match_obj1)match_obj2 = re.search(r'amo_w+', '項目名稱Amo_SHOP amo_shop', re.I)print(match_obj2)
執行結果如下:
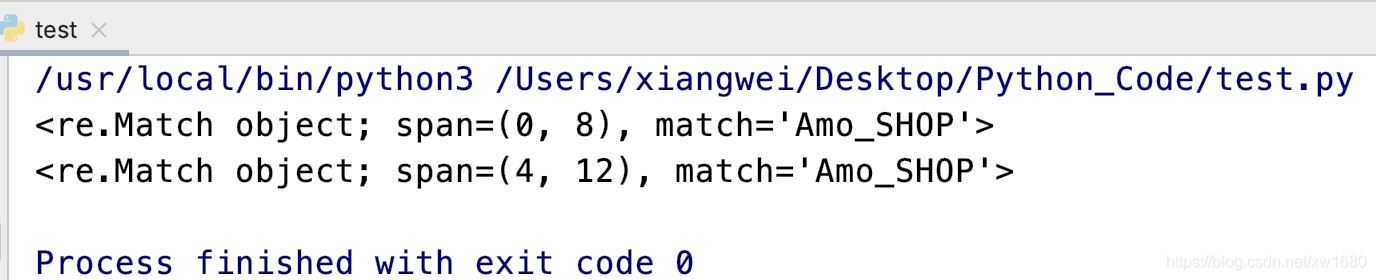
從上面的運行結果中可以看出,search()方法不僅僅是在字符串的起始位置搜索,其他位置有符合的匹配也可以。
7.2 使用findall()方法進行匹配findall()方法用于在整個字符串中搜索所有符合正則表達式的字符串,并以列表的形式返回。如果匹配成功,則返回包含匹配結構的列表,否則返回空列表。其語法格式如下:
re. findall(pattern, string, [flags])
參數說明:
pattern:表示模式字符串,由要匹配的正則表達式轉換而來。 string:表示要匹配的字符串。 flags:可選參數,表示標志位,用于控制匹配方式,如是否區分字母大小寫。例如,搜索以amo_開頭的字符串,不區分字母大小寫,代碼如下:
import reresult1 = re.findall(r'amo_w+', 'Amo_SHOP amo_shop', re.I)print(result1)result2 = re.findall(r'amo_w+', '項目名稱Amo_SHOP amo_shop')print(result2)
執行結果如下:
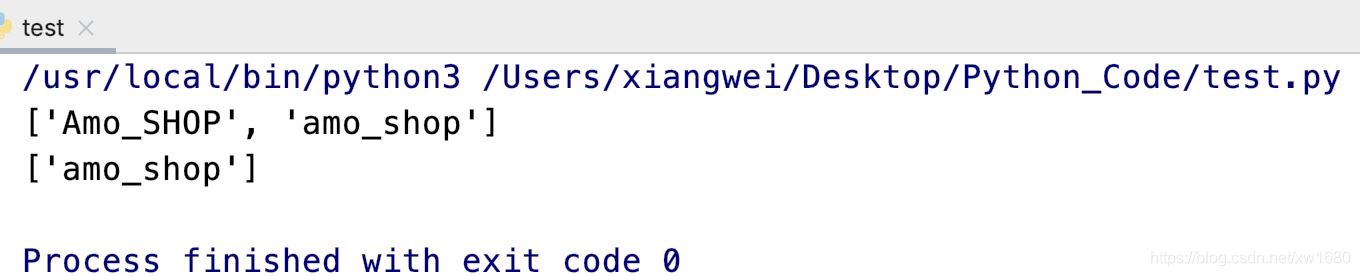
如果在指定的模式字符串中,包含分組,則返回與分組匹配的文本列表。例如:
import reresult1 = re.findall(r'[1-9]{1,3}(.[0-9]{1,3}){3}', '127.0.0.1 192.168.31.157')print(result1)
上面的代碼的執行結果如下:
[’.1’, ’.157’]
從上面的結果中可以看出,并沒有得到匹配的IP地址,這是因為在模式字符串中出現了分組,所以得到的結果是根據分組進行匹配的結果,即(.[0一9]{1,3})匹配的結果。如果想獲取整個模式字符串的匹配,可以將整個模式字符串使用一對小括號進行分組,然后在獲取結果時,只取返回值列表的每個元素(是一個元組)的第1個元素。代碼如下:
import restr1 = '127.0.0.1 192.168.31.157'result1 = re.findall(r'([1-9]{1,3}(.[0-9]{1,3}){3})', str1)for item in result1: print(item[0])
執行結果如下:
127.0.0.1192.168.31.157
7.3 替換字符串sub()方法用于實現字符串替換,語法格式如下:
re. sub( pattern, repl, string, count, flags)
參數說明:
pattern:表示模式字符串,由要匹配的正則表達式轉換而來。 repl: 表示替換的字符串。 string:表示要被查找替換的原始字符串。 count:可選參數,表示模式匹配后替換的最大次數,默認值為0,表示替換所有的匹配。 flags:可選參數,表示標志位,用于控制匹配方式,如是否區分字母大小寫。例如,隱藏中獎信息中的手機號碼,代碼如下:
import repattern = r'1[34578]d{9}'str1 = '中獎號碼為: 84978981 聯系電話為: 13611111111'result = re.sub(pattern, '1XXXXXXXXXX', str1)print(result)
執行結果如下:
中獎號碼為: 84978981 聯系電話為: 1XXXXXXXXXX
7.4 使用正則表達式分割字符串split()方法用于實現根據正則表達式分割字符串,并以列表的形式返回,其作用與字符串對象的split()方法類似,所不同的就是分割字符由模式字符串指定。語法格式如下:
re.split(pattern, string, [maxsplit], [flags])
參數說明:
pattern:表示模式字符串,由要匹配的正則表達式轉換而來。 string:表示要匹配的字符串。 maxsplit:可選參數,表示最大的拆分次數。 flags:可選參數,表示標志位,用于控制匹配方式,如是否區分字母大小寫。例如,從給定的URL地址中提取出請求地址和各個參數,代碼如下:
import repattern = r'[?|&]'url = 'https://study.163.com/courses-search?keyword=python&username=amo'result = re.split(pattern, url)print(result)
執行結果如下:
[’https://study.163.com/courses-search’, ’keyword=python’, ’username=amo’]
關于正則表達式的貪婪和非貪婪 可以點擊這里正則表達式的貪婪模式與非貪婪模式參考。
到此這篇關于Python使用正則表達式實現爬蟲數據抽取的文章就介紹到這了,更多相關Python 正則表達式數據抽取內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備