Python 解析庫json及jsonpath pickle的實現


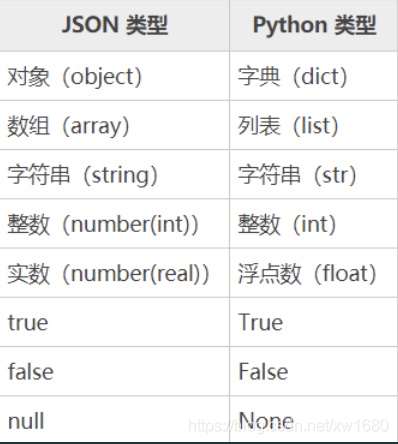
json模塊是Python內置標準庫,主要可以完成兩個功能:序列化和反序列化。JSON對象和Python對象映射圖如下:
3.2.1 json序列化
對象(字典/列表) 通過 json.dump()/json.dumps() ==> json字符串。示例代碼如下:
import jsonclass Phone(object): def __init__(self, name, price): self.name = name self.price = priceclass Default(json.JSONEncoder): def default(self, o): print(o) # o: <__main__.Phone object at 0x10aa52c90> return [o.name, o.price]def parse(obj): print(obj) return {'name': obj.name, 'price': obj.price}person_info_dict = { 'name': 'Amo', 'age': 18, 'is_boy': True, # 'n': float('nan'), # float('nan'):NaN float('inf')=>Infinity float('-inf')=>-Infinity 'phone': Phone('蘋果8plus', 6458), 'hobby': ('sing', 'dance'), 'dog': { 'name': '藏獒', 'age': 5, 'color': '棕色', 'isVIP': True, 'child': None },}'''obj:需要序列化的對象 字典/列表 這里指的是person_info_dictindent: 縮進 單位: 字符sort_keys: 是否按key排序 默認是False不排序cls: json.JSONEncoder子類 處理不能序列化的對象ensure_ascii: 是否確保ascii編碼 默認是True確保 '蘋果8plus'==>'u82f9u679c8plus' 所以改為Falsedefault: 對象不能被序列化時,調用對應的函數解析'''# 將結果返回給一個變量result = json.dumps(person_info_dict, indent=2, sort_keys=True, ensure_ascii=False, # cls=Default, default=parse, # allow_nan=False 是否處理特殊常量值 # 默認為True 但是JSON標準規范不支持NaN, Infinity和-Infinity )print(result)with open('dump.json', 'w', encoding='utf8') as file: # json.dump是將序列化后的內容存儲到文件中 其他參數用法和dumps一致 json.dump(person_info_dict, file, indent=4, ensure_ascii=False, default=parse)
3.2.2 json反序列化
json字符串通過json.load()/json.loads()==> 對象(字典/列表),示例代碼如下:
import jsonclass Phone(object): def __init__(self, name, price): self.name = name self.price = pricedef pi(num): return int(num) + 1def oh(dic): if 'price' in dic.keys(): return Phone(dic['name'], dic['price']) return dicdef oph(*args, **kwargs): print(*args, **kwargs)# 我自己本地有一個dump.json文件with open('dump.json', 'r', encoding='utf8') as file: # content = file.read() # parse_int/float: 整數/浮點數鉤子函數 # object_hook: 對象解析鉤子函數 將字典轉為特定對象 傳遞給函數的是字典對象 # object_pairs_hook: 轉化為特定對象 傳遞的是元組列表 # parse_constant: 常量鉤子函數 NaN/Infinity/-Infinity # result = json.loads(content, object_hook=oh, parse_int=pi, object_pairs_hook=oph) result = json.load(file, parse_int=pi, object_hook=oh) # 直接將文件對象傳入 print(type(result)) # <class ’dict’> print(result)4. jsonpath
jsonpath三方庫,點擊這里這里進入官網,通過路徑表達式,來快速獲取字典當中的指定數據,靈感來自xpath表達式。命令安裝:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com jsonpath
或者:

語法格式如下:
from jsonpath import jsonpathdic = {....} # 要找數據的字典jsonpath(dic, 表達式)
常用的表達式語法如下:
JSONPath 描述 $ 根節點(假定的外部對象,可以理解為上方的dic) @ 現行節點(當前對象) .或者[] 取子節點(子對象) .. 就是不管位置,選擇所有符合條件的節點(后代對象) * 匹配所有元素節點 [] 迭代集合,謂詞條件,下標 [,] 多選 ?() 支持過濾操作 () 支持表達式操作 [start: end : step] 切片
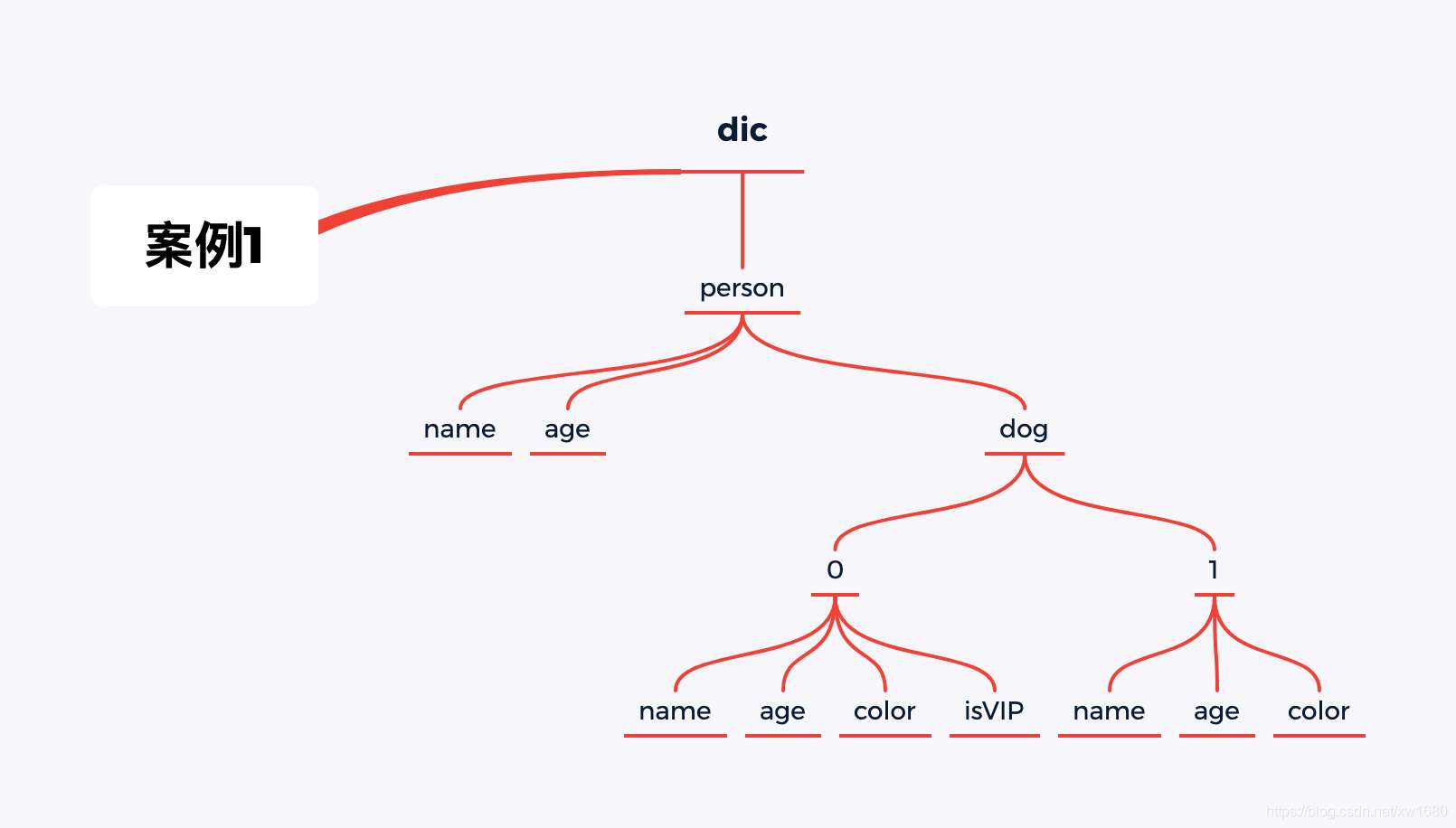
4.2 使用示例案例一用到的字典如下:
dic = { 'person': { 'name': 'Amo', 'age': 18, 'dog': [{ 'name': '小花', 'color': 'red', 'age': 6, 'isVIP': True }, { 'name': '小黑', 'color': 'black', 'age': 2 }] }}
將上述抽象成一個樹形結構如圖所示:
需求及結果如下:
JSONPath Result $.person.age 獲取人的年齡 $..dog[1].age 獲取第2個小狗的年齡 $..dog[0,1].age | $..dog[*].age 獲取所有小狗的年齡 $..dog[?(@.isVIP)] 獲取是VIP的小狗 $..dog[?(@.age>2)] 獲取年齡大于2的小狗 $..dog[-1:] | $..dog[(@.length-1)] 獲取最后一個小狗
代碼如下:
from jsonpath import jsonpathdic = { 'person': { 'name': 'Amo', 'age': 18, 'dog': [{ 'name': '小花', 'color': 'red', 'age': 6, 'isVIP': True }, { 'name': '小黑', 'color': 'black', 'age': 2 }] }}# 1.獲取人的年齡print(jsonpath(dic, '$.person.age')) # 獲取到數據返回一個列表 否則返回False# 2.獲取第2個小狗的年齡print(jsonpath(dic, '$..dog[1].age'))# 3.獲取所有小狗的年齡print(jsonpath(dic, '$..dog[0,1].age'))print(jsonpath(dic, '$..dog[*].age'))# 4.獲取是VIP的小狗print(jsonpath(dic, '$..dog[?(@.isVIP)]'))# 5.獲取年齡大于2的小狗print(jsonpath(dic, '$..dog[?(@.age>2)]'))# 6.獲取最后一個小狗print(jsonpath(dic, '$..dog[-1:]'))print(jsonpath(dic, '$..dog[(@.length-1)]'))
上述代碼執行結果如下:

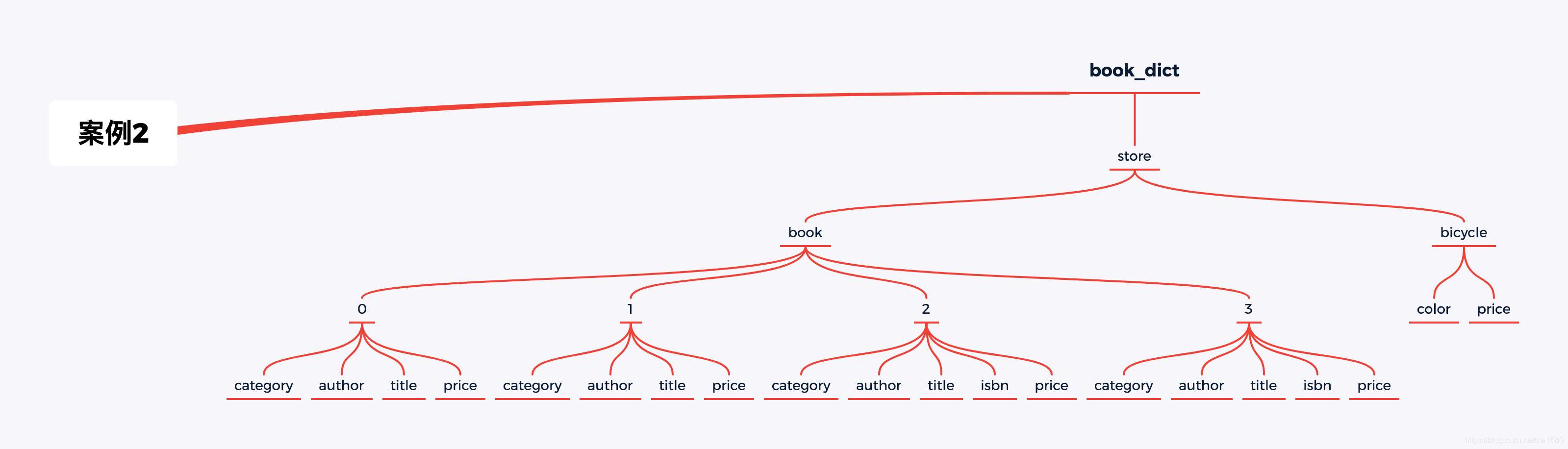
案例二用到的字典如下:
book_dict = { 'store': { 'book': [ {'category': 'reference', 'author': 'Nigel Rees', 'title': 'Sayings of the Century', 'price': 8.95 }, {'category': 'fiction', 'author': 'Evelyn Waugh', 'title': 'Sword of Honour', 'price': 12.99 }, {'category': 'fiction', 'author': 'Herman Melville', 'title': 'Moby Dick', 'isbn': '0-553-21311-3', 'price': 8.99 }, {'category': 'fiction', 'author': 'J. R. R. Tolkien', 'title': 'The Lord of the Rings', 'isbn': '0-395-19395-8', 'price': 22.99 } ], 'bicycle': { 'color': 'red', 'price': 19.95 } }}
將上述抽象成一個樹形結構如圖所示:
需求及結果如下:
JSONPath Result $.store.book[*].author store中的所有的book的作者 $.store[*] store下的所有的元素 $..price store中的所有的內容的價格 $..book[2] 第三本書 $..book[(@.length-1)] 最后一本書 $..book[0:2] 前兩本書 $.store.book[?(@.isbn)] 獲取有isbn的所有書 $.store.book[?(@.price>10)] 獲取價格大于10的所有的書 $..* 獲取所有的數據
代碼如下:
from jsonpath import jsonpathbook_dict = { 'store': { 'book': [ {'category': 'reference', 'author': 'Nigel Rees', 'title': 'Sayings of the Century', 'price': 8.95 }, {'category': 'fiction', 'author': 'Evelyn Waugh', 'title': 'Sword of Honour', 'price': 12.99 }, {'category': 'fiction', 'author': 'Herman Melville', 'title': 'Moby Dick', 'isbn': '0-553-21311-3', 'price': 8.99 }, {'category': 'fiction', 'author': 'J. R. R. Tolkien', 'title': 'The Lord of the Rings', 'isbn': '0-395-19395-8', 'price': 22.99 } ], 'bicycle': { 'color': 'red', 'price': 19.95 } }}# 1.store中的所有的book的作者print(jsonpath(book_dict, '$.store.book[*].author'))print(jsonpath(book_dict, '$..author'))# 2.store下的所有的元素print(jsonpath(book_dict, '$.store[*]'))print(jsonpath(book_dict, '$.store.*'))# 3.store中的所有的內容的價格print(jsonpath(book_dict, '$..price'))# 4.第三本書print(jsonpath(book_dict, '$..book[2]'))# 5.最后一本書print(jsonpath(book_dict, '$..book[-1:]'))print(jsonpath(book_dict, '$..book[(@.length-1)]'))# 6.前兩本書print(jsonpath(book_dict, '$..book[0:2]'))# 7.獲取有isbn的所有書print(jsonpath(book_dict, '$.store.book[?(@.isbn)]'))# 8.獲取價格大于10的所有的書print(jsonpath(book_dict, '$.store.book[?(@.price>10)]'))# 9.獲取所有的數據print(jsonpath(book_dict, '$..*'))5. Python專用JSON解析庫pickle
pickle處理的json對象不通用,可以額外的把函數給序列化。示例代碼如下:
import pickledef eat(): print('Amo在努力地寫博客~')person_info_dict = { 'name': 'Amo', 'age': 18, 'eat': eat}# print(pickle.dumps(person_info_dict))with open('pickle_json', 'wb') as file: pickle.dump(person_info_dict, file)with open('pickle_json', 'rb') as file: result = pickle.load(file) result['eat']()JsonPath與XPath語法對比:
Json結構清晰,可讀性高,復雜度低,非常容易匹配,下表中對應了XPath的用法。
XPath JSONPath 描述 / $ 根節點 . @ 現行節點 / .or[] 取子節點 .. n/a 取父節點,Jsonpath未支持 // .. 就是不管位置,選擇所有符合條件的條件 * * 匹配所有元素節點 @ n/a 根據屬性訪問,Json不支持,因為Json是個Key-value遞歸結構,不需要。 [] [] 迭代器標示(可以在里邊做簡單的迭代操作,如數組下標,根據內容選值等) | [,] 支持迭代器中做多選。 [] ?() 支持過濾操作. n/a () 支持表達式計算 () n/a 分組,JsonPath不支持
到此這篇關于Python 解析庫json及jsonpath pickle的實現的文章就介紹到這了,更多相關Python 解析庫json及jsonpath pickle內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備