淺談Python描述數據結構之KMP篇
前言
本篇章主要介紹串的KMP模式匹配算法及其改進,并用Python實現KMP算法。
1. BF算法
BF算法,即Bruce−ForceBruce-ForceBruce−Force算法,又稱暴力匹配算法。其思想就是將主串S的第一個字符與模式串T的第一個字符進行匹配,若相等,則繼續比較S的第二個字符和T的第二個字符;若不相等,則比較S的第二個字符和T的第一個字符,依次比較下去,直到得出最后的匹配結果。
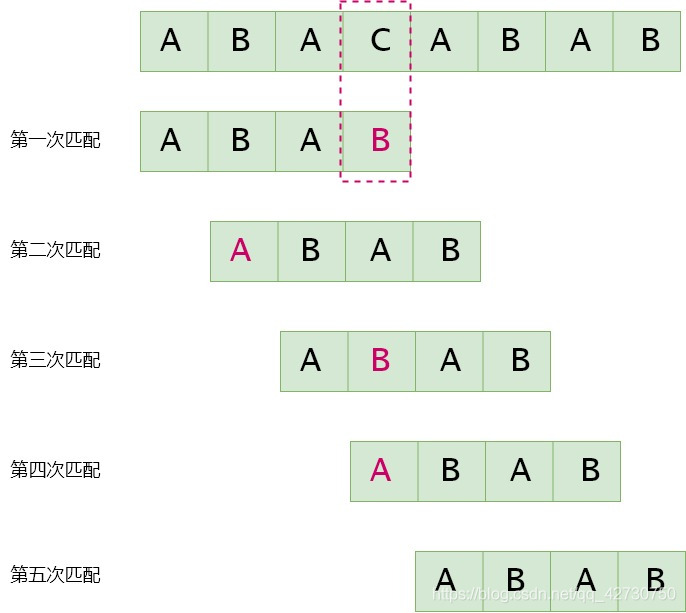
假設主串S=ABACABABS=ABACABABS=ABACABAB,模式串T=ABABT=ABABT=ABAB,每趟匹配失敗后,主串S指針回溯,模式串指針回到頭部,然后再次匹配,過程如下:
def BF(substrS, substrT): if len(substrT) > len(substrS): return -1 j = 0 t = 0 while j < len(substrS) and t < len(substrT): if substrT[t] == substrS[j]: j += 1 t += 1 else: j = j - t + 1 t = 0 if t == len(substrT): return j - t else: return -1
2. KMP算法
KMP算法,是由D.E.Knuth、J.H.Morris、V.R.PrattD.E.Knuth、J.H.Morris、V.R.PrattD.E.Knuth、J.H.Morris、V.R.Pratt同時發現的,又被稱為克努特-莫里斯-普拉特算法。該算法的基本思路就是在匹配失敗后,無需回到主串和模式串最近一次開始比較的位置,而是在不改變主串已經匹配到的位置的前提下,根據已經匹配的部分字符,從模式串的某一位置開始繼續進行串的模式匹配。
就是這次匹配失敗時,下次匹配時模式串應該從哪一位開始比較。
BF算法思路簡單,便于理解,但是在執行時效率太低。在上述的匹配過程中,第一次匹配時已經匹配的'ABA''ABA''ABA',其前綴與后綴都是'A''A''A',這個時候我們就不需要執行第二次匹配了,因為第一次就已經匹配過了,所以可以跳過第二次匹配,直接進行第三次匹配,即前綴位置移到后綴位置,主串指針無需回溯,并繼續從該位開始比較。
前綴:是指除最后一個字符外,字符串的所有頭部子串。 后綴:是指除第一個字符外,字符串的所有尾部子串。 部分匹配值(Partial(Partial(Partial Match,PM)Match,PM)Match,PM):字符串的前綴和后綴的最長相等前后綴長度。 例如,′a′’a’′a′的前綴和后綴都為空集,則最長公共前后綴長度為0;′ab′’ab’′ab′的前綴為{a}{a}{a},后綴為{b}{b}{b},則最長公共前后綴為空集,其長度長度為0;′aba′’aba’′aba′的前綴為{a,ab}{a,ab}{a,ab},后綴為{a,ba}{a,ba}{a,ba},則最長公共前后綴為{a}{a}{a},其長度長度為1;′abab′’abab’′abab′的前綴為{a,ab,aba}{a,ab,aba}{a,ab,aba},后綴為{b,ab,bab}{b,ab,bab}{b,ab,bab},則最長公共前后綴為{ab}{ab}{ab},其長度長度為2。 前綴一定包含第一個字符,后綴一定包含最后一個字符。
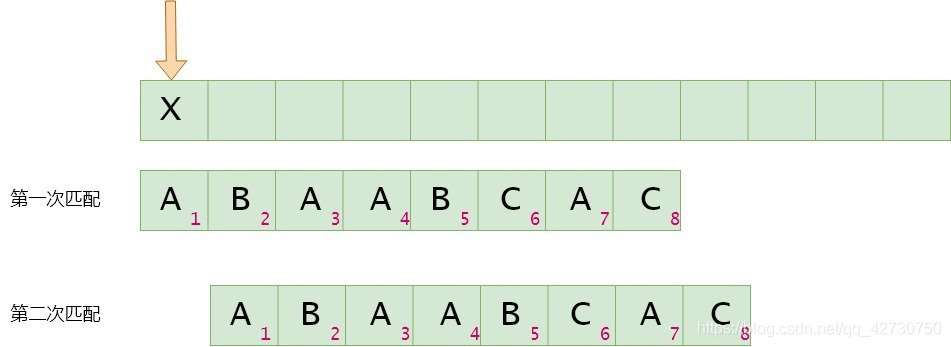
如果模式串1號位與主串當前位(箭頭所指的位置)不匹配,將模式串1號位與主串的下一位進行比較。next[0]=-1,這邊就是一個特殊位置了,即如果主串與模式串的第1位不相同,那么下次就直接比較各第2位的字符。
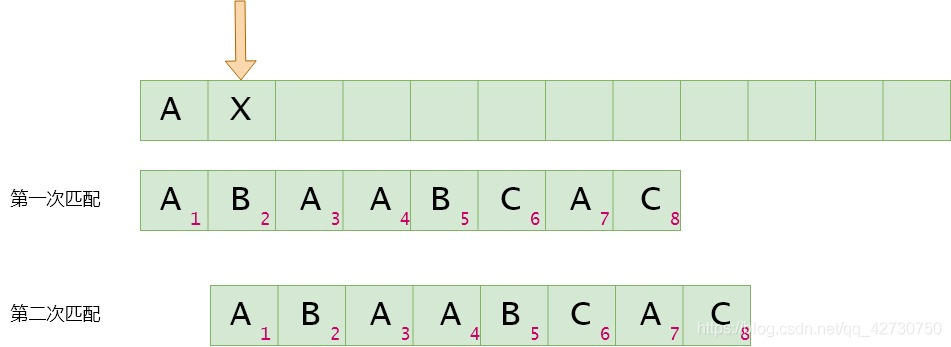
如果模式串2號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'A''A''A',即最長公共前后綴為空集,其長度為0,則下次匹配時將模式串1號位與主串的當前位進行比較。next[1]=0
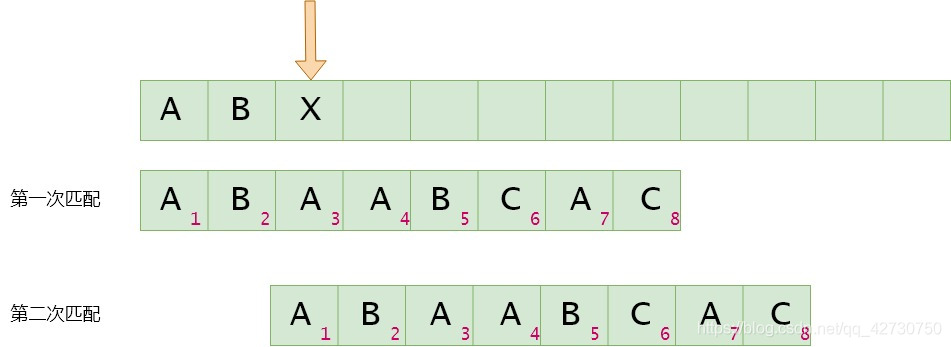
如果模式串3號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'AB''AB''AB',即最長公共前后綴為空集,其長度為0,則下次匹配時將模式串1號位與主串的當前位進行比較。next[2]=0
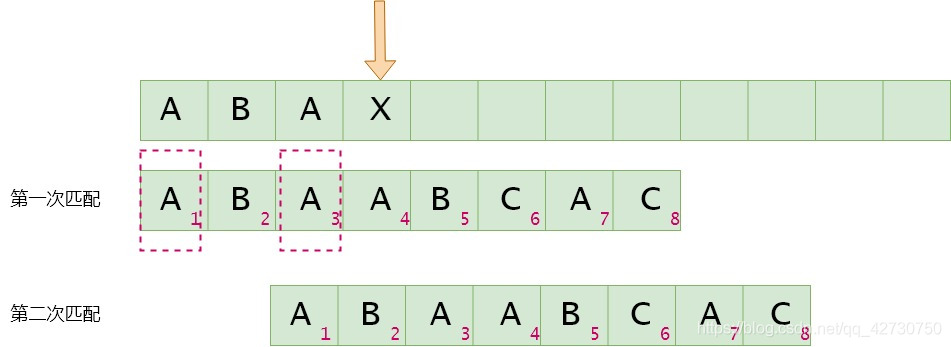
如果模式串4號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'ABA''ABA''ABA',即最長公共前后綴為'A''A''A',其長度為1,則下次匹配時將前綴位置移到后綴位置,即模式串2號位與主串的當前位進行比較。next[3]=1
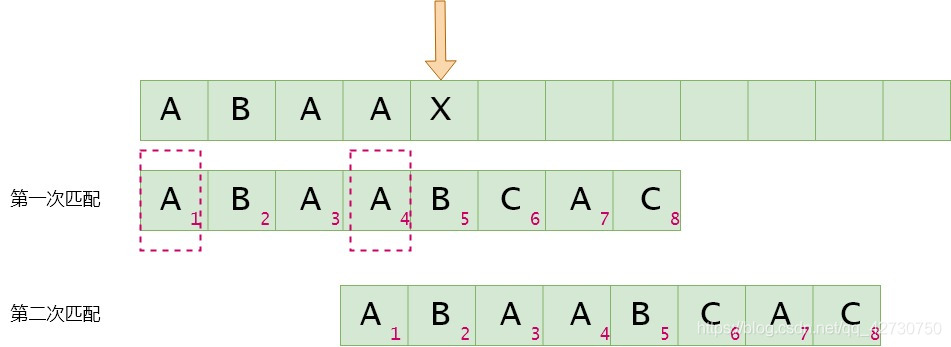
如果模式串5號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'ABAA''ABAA''ABAA',即最長公共前后綴為'A''A''A',其長度為1,則下次匹配時將前綴位置移到后綴位置,即模式串2號位與主串的當前位進行比較。next[4]=1
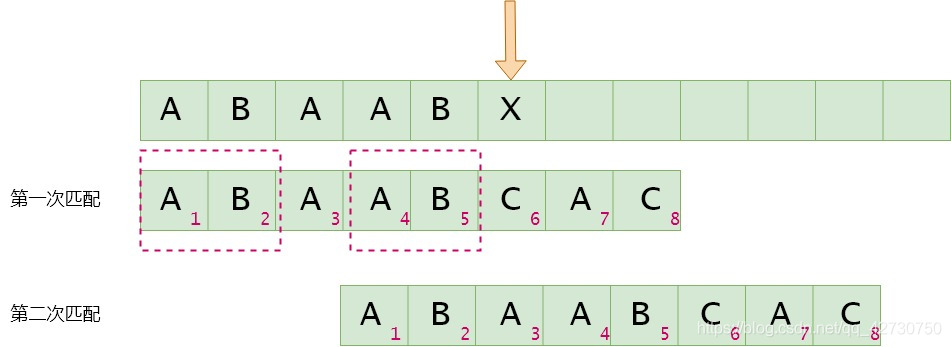
如果模式串6號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'ABAAB''ABAAB''ABAAB',即最長公共前后綴為'AB''AB''AB',其長度為2,則下次匹配時將前綴位置移到后綴位置,即模式串3號位與主串的當前位進行比較。next[5]=2
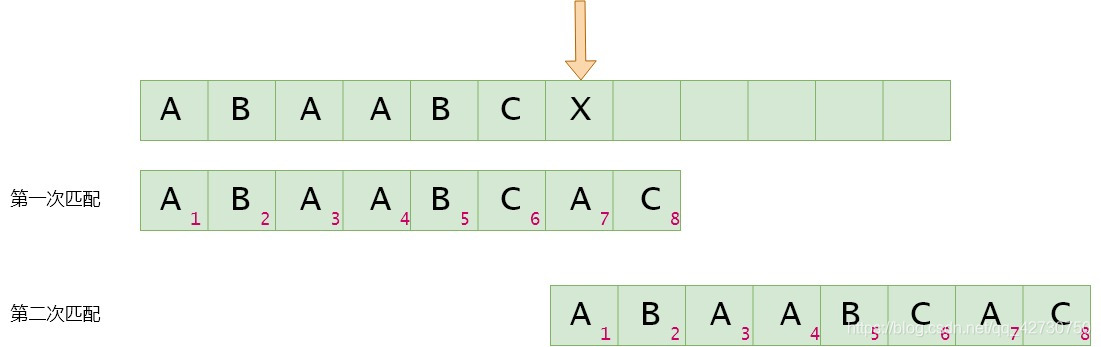
如果模式串7號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'ABAABC''ABAABC''ABAABC',即最長公共前后綴為空集,其長度為0,則下次匹配時將模式串1號位與主串的當前位進行比較。next[6]=0
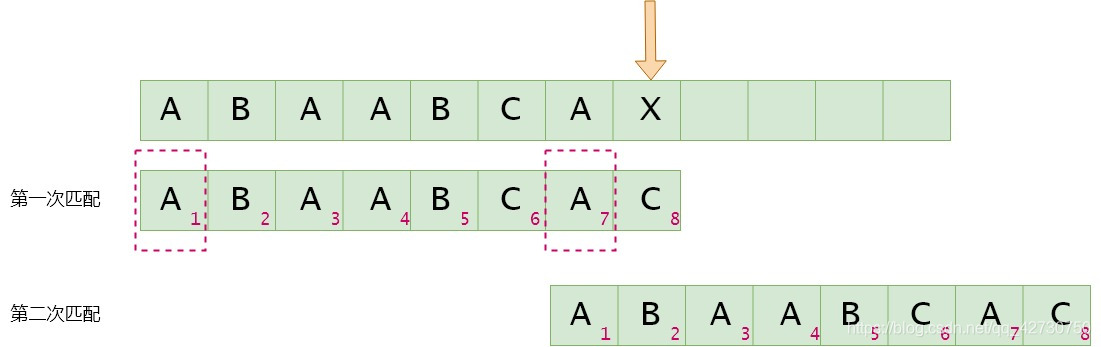
如果模式串8號位與主串當前位不匹配,找最長公共前后綴,指針前面的子串為'ABAABCA''ABAABCA''ABAABCA',即最長公共前后綴為'A''A''A',其長度為1,則下次匹配時將模式串2號位與主串的當前位進行比較。next[7]=1
綜上,可以得到模式串的next數組,發現沒有,把主串去掉也可以得到這個數組,即下次匹配時模式串向后移動的位數與主串無關,僅與模式串本身有關。
位編號 1 2 3 4 5 6 7 8 索引 0 1 2 3 4 5 6 7 模式串 A B A A B C A C next -1 0 0 1 1 2 0 1
next數組,即存放的是每個字符匹配失敗時,對應的下一次匹配時模式串開始匹配的位置。
如何在代碼里實現上述流程呢?舉個栗子,藍色方框圈出的就是公共前后綴,假設next[j]=t:
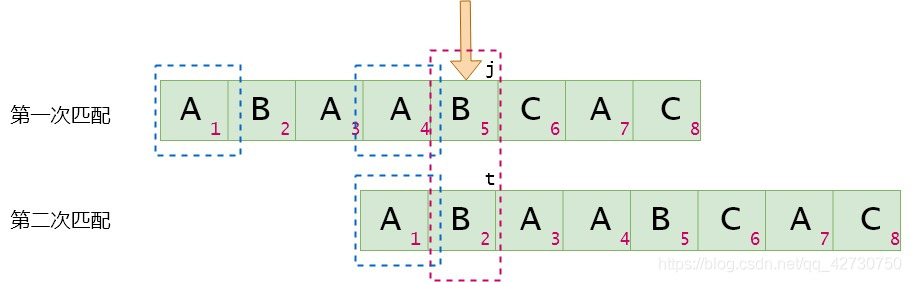
當Tj=TtT_j=T_tTj=Tt時,可以得到next[j+1]=t+1=next[j]+1next[j+1]=t+1=next[j]+1next[j+1]=t+1=next[j]+1。這個時候j=4,t=1j=4,t=1j=4,t=1(索引);
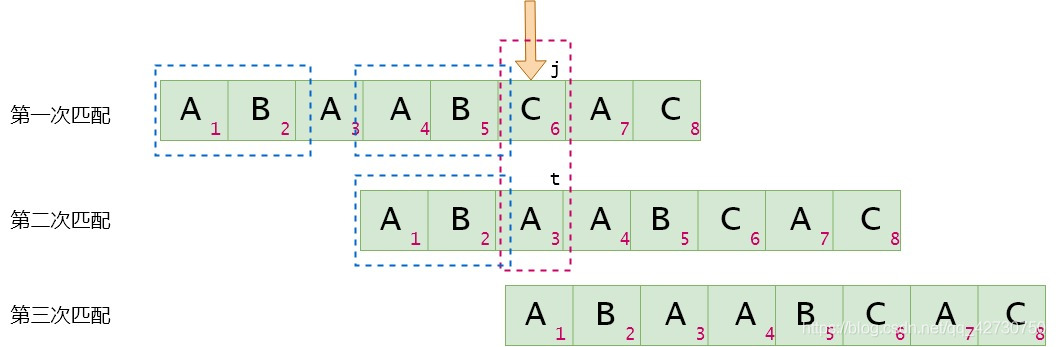
當Tj≠TtT_j neq T_tTj?=Tt時,即模式串ttt位置與主串(并不是真正的主串)不匹配,則將下面的那個模式串移動到next[t]next[t]next[t]位置進行比較,即t=next[t]t=next[t]t=next[t],直到Tj=TtT_j=T_tTj=Tt或t=−1t=-1t=−1,當t=−1t=-1t=−1時,next[j+1]=0next[j+1]=0next[j+1]=0。這里就是t=next[2]=0t=next[2]=0t=next[2]=0,即下次匹配時,模式串的第1位與主串當前位進行比較。
代碼如下:
def getNext(substrT): next_list = [-1 for i in range(len(substrT))] j = 0 t = -1 while j < len(substrT) - 1: if t == -1 or substrT[j] == substrT[t]: j += 1 t += 1 # Tj=Tt, 則可以到的next[j+1]=t+1 next_list[j] = t else: # Tj!=Tt, 模式串T索引為t的字符與當前位進行匹配 t = next_list[t] return next_listdef KMP(substrS, substrT, next_list): count = 0 j = 0 t = 0 while j < len(substrS) and t < len(substrT): if substrS[j] == substrT[t] or t == -1: # t == -1目的就是第一位匹配失敗時 # 主串位置加1, 匹配串回到第一個位置(索引為0) # 匹配成功, 主串和模式串指針都后移一位 j += 1 t += 1 else: # 匹配失敗, 模式串索引為t的字符與當前位進行比較 count += 1 t = next_list[t] if t == len(substrT): # 這里返回的是索引 return j - t, count+1 else: return -1, count+1
3. KMP算法優化版
上面定義的next數組在某些情況下還有些缺陷,發現沒有,在第一個圖中,我們還可以跳過第3次匹配,直接進行第4次匹配。為了更好地說明問題,我們以下面這種情況為例,來優化一下KMP算法。假設主串S=AAABAAAABS=AAABAAAABS=AAABAAAAB,模式串T=AAAABT=AAAABT=AAAAB,按照KMP算法,匹配過程如下:
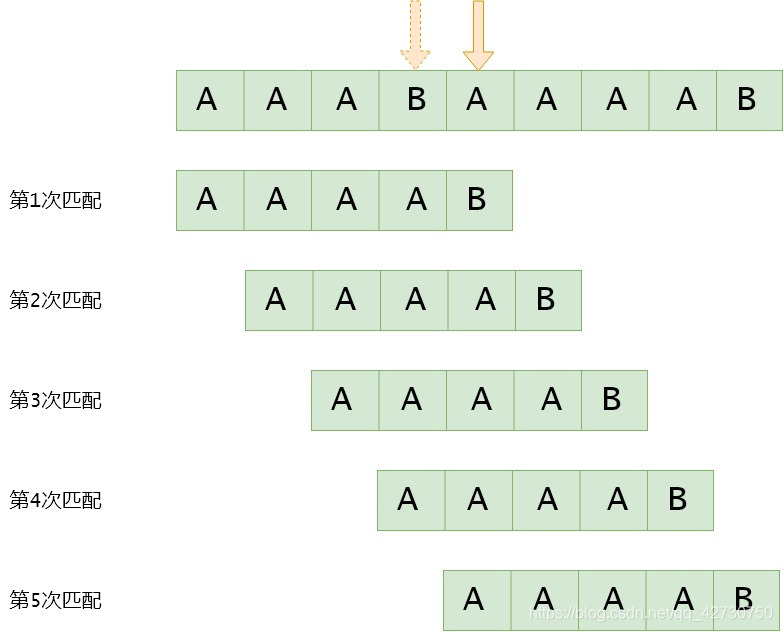
可以看到第2、3、4次的匹配是多余的,因為我們在第一次匹配時,主串SSS的4號位為模式串TTT的4號位就已經比較了,且T3≠S3T_3 neq S_3T3?=S3,又因為模式串TTT的4號位與其1、2、3號位的字符一樣,即T3=T2=T1=T0≠S3T_3=T_2=T_1=T_0 neq S_3T3=T2=T1=T0?=S3,所以可以直接進入第5次匹配。
那么,問題出在哪里???我們結合著next數組看一下:
位編號 1 2 3 4 5 索引 0 1 2 3 4 模式串 A A A A B next -1 0 1 2 3
問題在于,當Tj≠SjT_j neq S_jTj?=Sj時,下次匹配的必然是Tnext[j]T_{next[j]}Tnext[j]與SjS_jSj,如果這時Tnext[j]=TjT_{next[j]} = T_jTnext[j]=Tj,那么又相當于TjT_jTj與SjS_jSj進行比較,因為它們的字符一樣,毫無疑問,這次匹配是沒有意義的,應當將next[j]next[j]next[j]的值直接賦值為-1,即遇到這種情況,主串與模式串都從下一位開始比較。
所以,我們要修正一下next數組。
大致流程和上面求解next數組時一樣,這里就是多了一個判別條件,如果在匹配時出現了Tnext[j]=TjT_{next[j]} = T_jTnext[j]=Tj,我們就將next[j]更新為next[Big[[next[j]]Big]],直至兩者不相等為止(相當于了迭代)。在代碼里面實現就是,如果某個字符已經相等或者第一個next[j]數組值為-1(即t=−1t=-1t=−1),且主串和模式串指針各后移一位時的字符仍然相同,那么就將當前的next[j]值更新為上一個next[j]數組值,更新后的數組命名為nextval。
代碼如下:
def getNextval(substrT): nextval_list = [-1 for i in range(len(substrT))] j = 0 t = -1 while j < len(substrT) - 1: if t == -1 or substrT[j] == substrT[t]: j += 1 t += 1 if substrT[j] != substrT[t]:# Tj=Tt, 但T(j+1)!=T(t+1), 這個就和next數組計算時是一樣的# 可以得到nextval[j+1]=t+1nextval_list[j] = t else:# Tj=Tt, 且T(j+1)==T(t+1), 這個就是next數組需要更新的# nextval[j+1]=上一次的nextval_list[t]nextval_list[j] = nextval_list[t] else: # 匹配失敗, 模式串索引為t的字符與當前位進行比較 t = nextval_list[t] return nextval_list
對KMP的優化其實就是對next數組的優化,修正后的next數組,即nextval數組如下:
位編號 1 2 3 4 5 索引 0 1 2 3 4 模式串 A A A A B nextval -1 -1 -1 -1 3
下面就測試一下:
if __name__ == ’__main__’: S1 = ’ABACABAB’ T1 = ’ABAB’ S2 = ’AAABAAAAB’ T2 = ’AAAAB’ print(’*’ * 50) print(’主串S={0}與模式串T={1}進行匹配’.format(S1, T1)) print(’{:*^25}’.format(’KMP’)) next_list1 = getNext(T1) print(’next數組為: {}’.format(next_list1)) index1_1, count1_1 = KMP(S1, T1, next_list1) print(’匹配到的位置(索引): {}, 匹配次數: {}’.format(index1_1, count1_1)) print(’{:*^25}’.format(’KMP優化版’)) nextval_list1 = getNextval(T1) print(’nextval數組為: {}’.format(nextval_list1)) index1_2, count1_2 = KMP(S1, T1, nextval_list1) print(’匹配到的位置(索引): {}, 匹配次數: {}’.format(index1_2, count1_2)) print(’’) print(’*’ * 50) print(’主串S={0}與模式串T={1}進行匹配’.format(S2, T2)) print(’{:*^25}’.format(’KMP’)) next_list2 = getNext(T2) print(’next數組為: {}’.format(next_list2)) index2_1, count2_1 = KMP(S2, T2, next_list2) print(’匹配到的位置(索引): {}, 匹配次數: {}’.format(index2_1, count2_1)) print(’{:*^25}’.format(’KMP優化版’)) nextval_list2 = getNextval(T2) print(’nextval數組為: {}’.format(nextval_list2)) index2_2, count2_2 = KMP(S2, T2, nextval_list2) print(’匹配到的位置(索引): {}, 匹配次數: {}’.format(index2_2, count2_2))
運行結果如下:
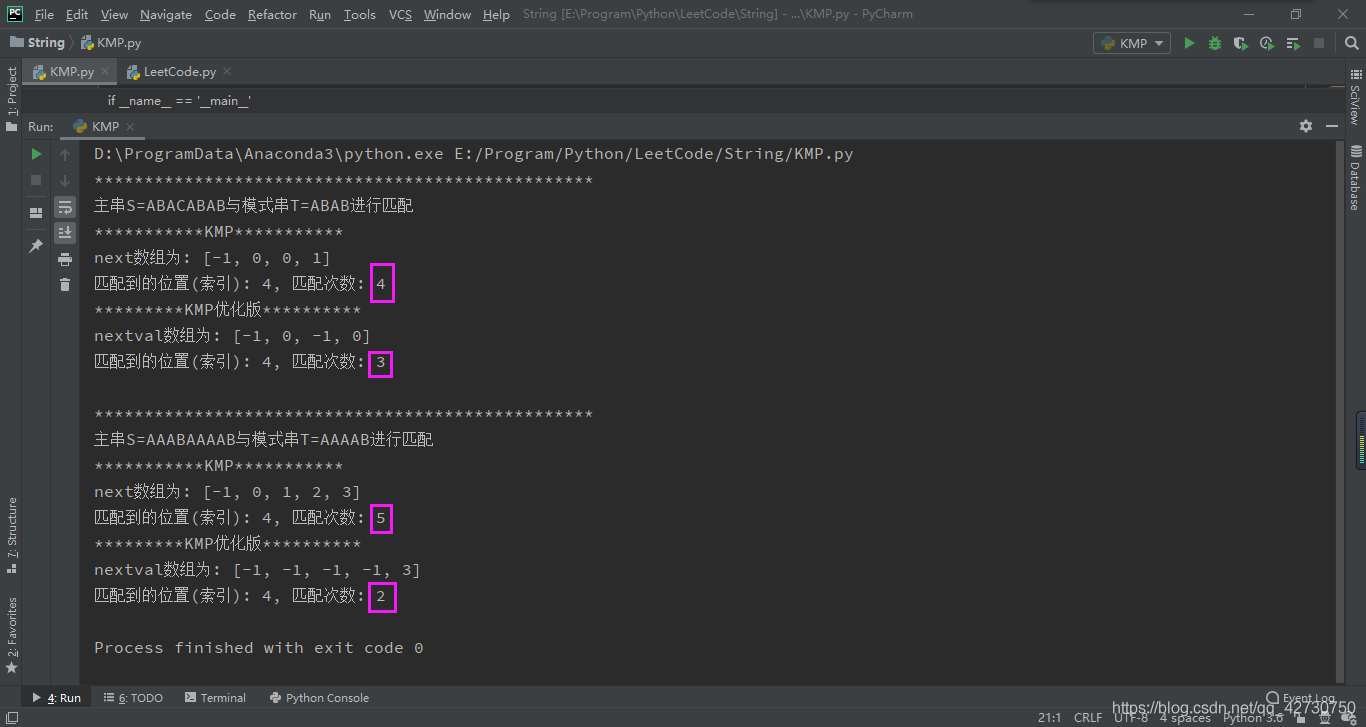
運行的結果和我們分析的是一樣的,不修正next數組時,主串S=ABACABABS=ABACABABS=ABACABAB與模式串T=ABABT=ABABT=ABAB匹配時需要4次,主串S=AAABAAAABS=AAABAAAABS=AAABAAAAB與模式串T=AAAABT=AAAABT=AAAAB匹配時需要5次;修正next數組后,主串S=ABACABABS=ABACABABS=ABACABAB與模式串T=ABABT=ABABT=ABAB匹配時需要3次,主串S=AAABAAAABS=AAABAAAABS=AAABAAAAB與模式串T=AAAABT=AAAABT=AAAAB匹配時僅需要2次。
結束語
在寫本篇博客之前也是反復看參考書、視頻,邊畫圖邊去理解它,這篇博客也是反復修改了好幾次,最終算是把KMP解決掉了,有關字符串知識的復習也算是基本結束,下面就是刷題了(雖然在LeetCode做過了幾道題)。
到此這篇關于Python描述數據結構之KMP篇的文章就介紹到這了,更多相關Python KMP內容請搜索好吧啦網以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持好吧啦網!
相關文章:
 網公網安備
網公網安備