Python Pivot table透視表使用方法解析
Pivot 及 Pivot_table函數用法
Pivot和Pivot_table函數都是對數據做透視表而使用的。其中的區別在于Pivot_table可以支持重復元素的聚合操作,而Pivot函數只能對不重復的元素進行聚合操作。
在一般的日常業務中,因為Pivot_table的功能更為強大,Pivot能做的不能做的Pivot_table都可做。所以只需要記住Pivot_table函數用法就好了。
Pivot函數的使用演示
#%%import pandas as pddf01 = pd.DataFrame( { '年份':[2019,2019,2019,2020,2020,2020], '平臺':['京東','淘寶','拼多多','京東','淘寶','拼多多'], '銷量':[100,200,300,400,500,600] })df01#%%pd.pivot(df01, index = '年份', columns = '平臺', values = '銷量')#%%
聚合后結果

Pivot_table函數的使用演示
注釋:index指定什么元素作為index顯示,columns指定列,values指定統計的值。一般values都為int后者float類型的值。aggfunc為聚合函數可以指定(mean,sum,Min,Max等統計運算等函數,如果不指定默認為mean均值)
df02 = pd.DataFrame( { '年份':[2019,2019,2019,2019,2020,2020,2020,2020], '平臺':['京東','淘寶','淘寶','拼多多','京東','淘寶','拼多多','拼多多'], '銷量':[100,200,300,400,500,600,700,800] })df02#%%#pivot_table用的很多.因為可以對重復的元素進行聚合操作.而pivot函數只能對不重復的行進行運算pd.pivot_table(df02,index='年份',columns='平臺',values='銷量',aggfunc=sum #聚合函數來對銷量進行運算.可以指定最大,最小,平均值等函數.默認為mean平均值)#%%
聚合結果

對比結果:這里要強調一點的是,2020年平臺為拼多多的數據出現了2次,而且2次的值不同。在pivot函數中是無法對這種重復平臺的數據進行聚合的,但是Pivot_table則可以。
另外通過聚合函數aggfunc指定sum求和,可以把2次的值累加統計。
Pivot_table函數真實案例演示
1. 讀取表格數據
#%%df = pd.read_excel('./datas/result_datas.xlsx', ).convert_dtypes() #讀取數據并自動轉化typedf.dtypes#%%df.head(3)#%%

2. 通過Pivot_table函數透視合并數據并對金額和數量做統計
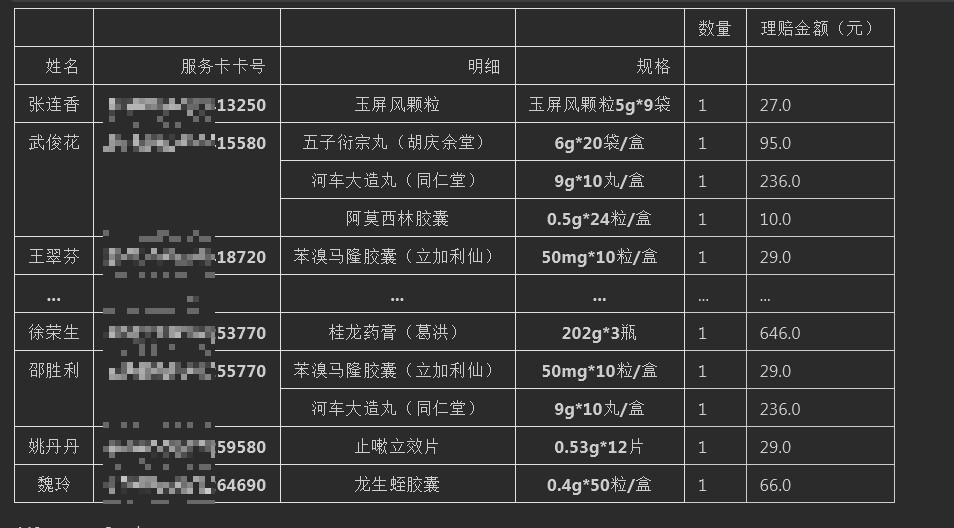
因為涉及到敏感信息,因此服務卡卡號等敏感信息部分遮掩不顯示。但是通過部分結果也可以看出是按照號碼進行升序排序的
#按照自定義指定index,columns,values值result = pd.pivot_table(df,index = ['姓名','服務卡卡號','明細','規格'],values = ['理賠金額(元)','數量'],aggfunc=sum)result = result.sort_values('服務卡卡號') #按照指定values值排序result#%%#輸出到文件result.to_excel('./datas/output_datas.xlsx')print('Done!!!')
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持好吧啦網。
相關文章:

 網公網安備
網公網安備