Python實現(xiàn)一個論文下載器的過程
在科研學(xué)習(xí)的過程中,我們難免需要查詢相關(guān)的文獻(xiàn)資料,而想必很多小伙伴都知道SCI-HUB,此乃一大神器,它可以幫助我們搜索相關(guān)論文并下載其原文。可以說,SCI-HUB造福了眾多科研人員,用起來也是“美滋滋”。

然而,當(dāng)師姐告訴我:“xx,可以幫我下載幾篇文獻(xiàn)嘛?”。樂心助人的我自當(dāng)是滿口答應(yīng)了,心想:“這種小事就交給我叭~”
于是乎,我收到了一個excel文檔,66篇論文的列表安靜地趟在里面(此刻心中碎碎念:“這尼瑪,是幾篇嘛...”)。我粗略算了一下,復(fù)制、粘貼、下載,一套流程走下來,每篇論文少說也得30秒,66篇的話....啊,這不能忍!
很顯然,一篇一篇的下載,不是我的風(fēng)格所以,我決定寫一個論文下載器助我前行。
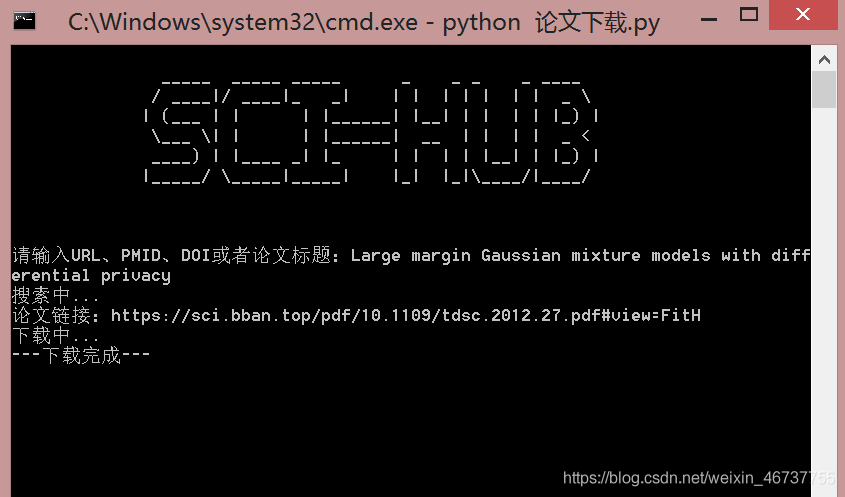
代碼分析的詳細(xì)思路跟以往依舊如此雷同,逃不過的還是:抓包分析->模擬請求->代碼整合。由于一會兒kimol君還得去搬磚,今天就不詳細(xì)展開了。
1. 搜索論文通過論文的URL、PMID、DOI號或者論文標(biāo)題等搜索到對應(yīng)的論文,并通過bs4庫找出PDF原文的鏈接地址,代碼如下:
def search_article(artName): ’’’ 搜索論文 --------------- 輸入:論文名 --------------- 輸出:搜索結(jié)果(如果沒有返回'',否則返回PDF鏈接) ’’’ url = ’https://www.sci-hub.ren/’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Content-Type’:’application/x-www-form-urlencoded’, ’Content-Length’:’123’, ’Origin’:’https://www.sci-hub.ren’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} data = {’sci-hub-plugin-check’:’’, ’request’:artName} res = requests.post(url, headers=headers, data=data) html = res.text soup = BeautifulSoup(html, ’html.parser’) iframe = soup.find(id=’pdf’) if iframe == None: # 未找到相應(yīng)文章 return ’’ else: downUrl = iframe[’src’] if ’http’ not in downUrl: downUrl = ’https:’+downUrl return downUrl2. 下載論文
得到了論文的鏈接地址之后,只需要通過requests發(fā)送一個請求,即可將其下載:
def download_article(downUrl): ’’’ 根據(jù)論文鏈接下載文章 ---------------------- 輸入:論文鏈接 ---------------------- 輸出:PDF文件二進制 ’’’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} res = requests.get(downUrl, headers=headers) return res.content二、完整代碼
將上述兩個函數(shù)整合之后,我的完整代碼如下:
# -*- coding: utf-8 -*-'''Created on Tue Jan 5 16:32:22 2021@author: kimol_love'''import osimport timeimport requestsfrom bs4 import BeautifulSoup def search_article(artName): ’’’ 搜索論文 --------------- 輸入:論文名 --------------- 輸出:搜索結(jié)果(如果沒有返回'',否則返回PDF鏈接) ’’’ url = ’https://www.sci-hub.ren/’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Content-Type’:’application/x-www-form-urlencoded’, ’Content-Length’:’123’, ’Origin’:’https://www.sci-hub.ren’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} data = {’sci-hub-plugin-check’:’’, ’request’:artName} res = requests.post(url, headers=headers, data=data) html = res.text soup = BeautifulSoup(html, ’html.parser’) iframe = soup.find(id=’pdf’) if iframe == None: # 未找到相應(yīng)文章 return ’’ else: downUrl = iframe[’src’] if ’http’ not in downUrl: downUrl = ’https:’+downUrl return downUrl def download_article(downUrl): ’’’ 根據(jù)論文鏈接下載文章 ---------------------- 輸入:論文鏈接 ---------------------- 輸出:PDF文件二進制 ’’’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} res = requests.get(downUrl, headers=headers) return res.content def welcome(): ’’’ 歡迎界面 ’’’ os.system(’cls’) title = ’’’ _____ _____ _____ _ _ _ _ ____ / ____|/ ____|_ _| | | | | | | | _ | (___ | | | |______| |__| | | | | |_) | ___ | | | |______| __ | | | | _ < ____) | |____ _| |_ | | | | |__| | |_) | |_____/ _____|_____| |_| |_|____/|____/ ’’’ print(title) if __name__ == ’__main__’: while True: welcome() request = input(’請輸入URL、PMID、DOI或者論文標(biāo)題:’) print(’搜索中...’) downUrl = search_article(request) if downUrl == ’’: print(’未找到相關(guān)論文,請重新搜索!’) else: print(’論文鏈接:%s’%downUrl) print(’下載中...’) pdf = download_article(downUrl) with open(’%s.pdf’%request, ’wb’) as f: f.write(pdf) print(’---下載完成---’) time.sleep(0.8)
不出所料,代碼一跑,我便輕松完成了師姐交給我的任務(wù),不香嘛?
到此這篇關(guān)于Python實現(xiàn)一個論文下載器的過程的文章就介紹到這了,更多相關(guān)python論文下載器內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. vue使用moment如何將時間戳轉(zhuǎn)為標(biāo)準(zhǔn)日期時間格式2. bootstrap select2 動態(tài)從后臺Ajax動態(tài)獲取數(shù)據(jù)的代碼3. js select支持手動輸入功能實現(xiàn)代碼4. php redis setnx分布式鎖簡單原理解析5. 《Java程序員修煉之道》作者Ben Evans:保守的設(shè)計思想是Java的最大優(yōu)勢6. CSS3中Transition屬性詳解以及示例分享7. Python數(shù)據(jù)相關(guān)系數(shù)矩陣和熱力圖輕松實現(xiàn)教程8. 如何在PHP中讀寫文件9. java加載屬性配置properties文件的方法10. 什么是Python變量作用域
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備