python爬取豆瓣電影排行榜(requests)的示例代碼
’’’ 爬取豆瓣電影排行榜 設計思路: 1、先獲取電影類型的名字以及特有的編號 2、將編號向ajax發(fā)送get請求獲取想要的數(shù)據(jù) 3、將數(shù)據(jù)存放進excel表格中’’’
環(huán)境部署:
軟件安裝:
Python 3.7.6
官網(wǎng)地址:https://www.python.org/
安裝地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe
PyCharm 2020.2.2 x64 位
官網(wǎng)地址:https://www.jetbrains.com/pycharm/download/#section=windows
參考教程:https://www.jb51.net/article/197466.htm
模塊安裝(打開cmd或powershell進行下面的命令安裝【前提需要有python】):安裝requests模塊、lxml模塊(發(fā)送請求,xpath獲取數(shù)據(jù))
pip install requests #(主要用來發(fā)送請求,獲取響應)pip install lxml #(主要引用里面的etree里面的xpath方法)
安裝xpathhelper插件(可以在網(wǎng)頁中復制相應的節(jié)點xpath路徑并查看)
1、下載地址:
鏈接: https://pan.baidu.com/s/1zfpnrnFtZaxrgqrUX9y5Yg
提取碼: fmsu
2、window平臺下: · 把文件的后綴名crx改為rar,然后解壓到同名文件夾中 · 打開谷歌的擴展程序 ——> 進入到管理管理擴展程序中 · 打開開發(fā)者模式,通過加載已解壓的擴展程序,將插件導入3、ios平臺下: · 直接將crx文件拖進擴展程序中
安裝xlwt模塊(將數(shù)據(jù)存放進excel表格)
pip install xlwt
項目中需要引入的模塊:
import requestsfrom lxml import etreeimport xlwtimport time
使用流程:
在列表中填寫所需要獲取的電影類型名 輸入開始時獲取的start以及獲取多少數(shù)據(jù)的limit 填寫所要輸出的excel表格的名字(代碼中默認douban.xls) 程序運行結束后打開excel驗證數(shù)據(jù)是否獲取 觀察自己所需的數(shù)據(jù)完整代碼:
# encoding=utf8# 編程者 :Alvin’’’ 爬取豆瓣電影排行榜 設計思路: 1、先獲取電影類型的名字以及特有的編號 2、將編號向ajax發(fā)送get請求獲取想要的數(shù)據(jù) 3、將數(shù)據(jù)存放進excel表格中’’’import requestsfrom lxml import etreeimport xlwtimport timeclass DouBan(): # 初始化數(shù)據(jù),獲取最外層的數(shù)據(jù) def __init__(self, name_list): self.headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.3', 'Connection': 'close', 'Referer': 'https://movie.douban.com/' } # 獲取最外層的數(shù)據(jù),并拿到url中的type中的name 和 類型 self.url = ’https://movie.douban.com/chart’ self.dydata_list = [] # 電影的類型名 self.name_list = name_list # 實例化excel表格對象 self.wb = xlwt.Workbook() # 通過電影的類型名字獲取對應的類型號 def get_data_typenum(self, name): for data in self.dydata_list: if data[’name’] == name: typenum =data[’dytype’] else: continue return typenum # 獲取數(shù)據(jù) def get_data_p1(self): response = requests.get(self.url , headers = self.headers) # 判斷長度是否足夠大 # print(len(response.content.decode())) return response.content.decode() # 獲取下一層的頁面數(shù)據(jù) def get_data_p2(self, typenum, num, limit): url = ’https://movie.douban.com/j/chart/top_list’ params = { ’type’: typenum, ’interval_id’: ’100:90’, ’action’:’’, ’start’: num*20, ’limit’: limit } response = requests.get(url,params=params,headers=self.headers) # print(response.json()) return response.json() # 處理數(shù)據(jù) def data_parse_p1(self, data): html = etree.HTML(data) data_list = html.xpath(’//div[@class='types']/span/a/@href’) # 用于收集類型名字 name_list = [] dytype_list = [] # 用于收集類型號 for data in data_list: name = data.split(’?’)[-1].split(’&’)[0].split(’=’)[-1] dytype = data.split(’?’)[-1].split(’&’)[1].split(’=’)[-1] name_list.append(name) dytype_list.append(dytype) for (name,dytype) in zip(name_list,dytype_list): dydict = {} dydict[’name’] = name dydict[’dytype’] = dytype self.dydata_list.append(dydict) # print(self.dydata_list) return self.dydata_list def data_parse_p2(self, data_list,name): print(len(data_list)) douban = self.wb.add_sheet(name) style = xlwt.XFStyle() # 初始化一個style對象,用來保存excel的樣式 font = xlwt.Font() # 創(chuàng)建一個font對象,用來保存對字體進行的操作 font.name = ’微軟雅黑’ # 字體設置為’微軟雅黑’ font.bold = True # 字體加粗 al = xlwt.Alignment() # 創(chuàng)建一個對齊對啊想,用來改變文本內(nèi)容的字體 style.font = font # 將字體信息保存到style對象中 style.alignment = al # 水平對齊方式、水平居中 al.horz = 0x02 # 垂直對齊方式、垂直居中 al.vert = 0x01 # 電影的標題 douban.col(0).width = 256 * 25 # 電影演員的名字 douban.col(1).width = 256 * 50 # 電影上映的年份 douban.col(2).width = 256 * 15 # 電影上映的國家 douban.col(3).width = 256 * 15 # 電影的標簽 douban.col(4).width = 256 * 20 # 電影的評分 douban.col(5).width = 256 * 8 # 豆瓣中該電影的頁面鏈接 douban.col(6).width = 256 * 40 douban.write(0, 0, ’電影標題’, style) douban.write(0, 1, ’電影演員名字’, style) douban.write(0, 2, ’電影上映年份’, style) douban.write(0, 3, ’電影上映國家’, style) douban.write(0, 4, ’電影標簽’, style) douban.write(0, 5, ’電影評分’, style) douban.write(0, 6, ’豆瓣中該電影的頁面鏈接’, style) row = 1 for data in data_list: # 電影的標題 title = data[’title’] # 電影演員的名字 actors = data[’actors’] # 電影上映的年份 release_date = data[’release_date’] # 電影上映的國家 regions = data[’regions’][0] # 電影的標簽 types = data[’types’] # 電影評分 score = data[’score’] # 豆瓣查看的鏈接 link = data[’url’] douban.write(row, 0, title) douban.write(row, 1, actors) douban.write(row, 2, release_date) douban.write(row, 3, regions) douban.write(row, 4, types) douban.write(row, 5, score) douban.write(row, 6, link) row += 1 self.wb.save(’douban.xls’) # 運行程序 def run(self, num, limit): # 獲取第一層中的所需要的類型名字和數(shù)字 self.data_parse_p1(self.get_data_p1()) for name in self.name_list: typenum = self.get_data_typenum(name) # 向指定的分類進行數(shù)據(jù)的訪問 data_list = self.get_data_p2(typenum,num,limit) # 對獲取的數(shù)據(jù)進行解析保存 self.data_parse_p2(data_list,name)if __name__ == ’__main__’: # 需要查看的類型 douban = DouBan([’喜劇’,’懸疑’,’驚悚’]) # 需要查看的開始值start,以及需要查看的數(shù)量limit douban.run(0,100) time.sleep(2)
效果圖pycharm 運行臺
excel表格顯示
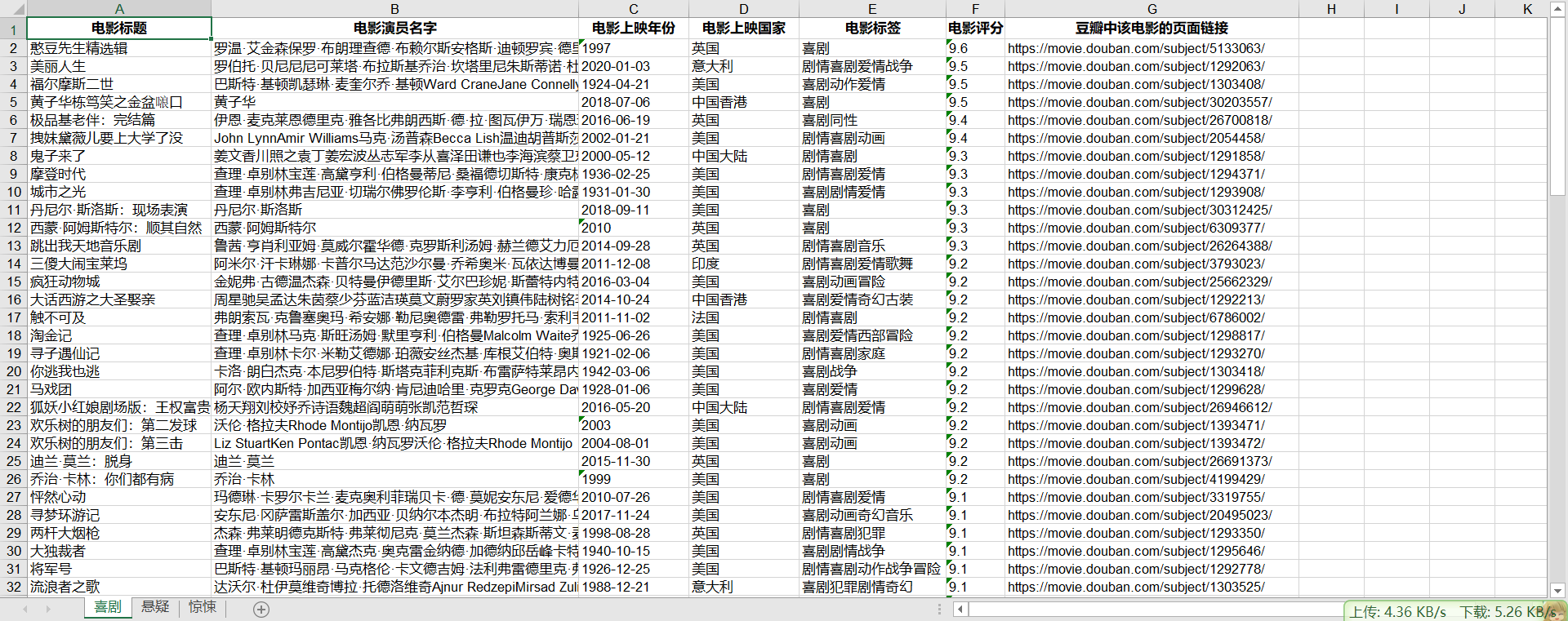
本案例筆者的想法是打算先獲取到每一個電影類型的前100個數(shù)據(jù),然后在excel表格中進行評分的篩選,最后觀察現(xiàn)階段某個電影類型中哪些電影在豆瓣電影中評分較高的
到此這篇關于python爬取豆瓣電影排行榜(requests)的文章就介紹到這了,更多相關python爬取豆瓣電影內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持好吧啦網(wǎng)!
相關文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備