python docx的超鏈接網址和鏈接文本操作
我就廢話不多說了,大家還是直接看代碼吧~
from docx import Documentfrom docx import RTimport red=Document('./liu2.docx')for p in d.paragraphs: rels = d.part.rels for rel in rels: if rels[rel].reltype == RT.HYPERLINK: print('n 超鏈接文本為', rels[rel], ' 超鏈接網址為: ', rels[rel]._target)
補充:Python輸出“test.docx“文檔正文中的所有紅色的文字、輸出文檔中所有的超鏈接地址和文本
一、題目:1、查閱資料了解.docx文檔結構,然后編寫程序,輸出'test.docx'文檔正文中的所有紅色的文字。
2、查閱資料了解.docx文檔結構,然后查閱資料,編寫程序,輸出'測試.docx'文檔中所有的超鏈接地址和文本。
3、已知文件“超市營業額1.xlsx”中記錄了某超市2019年3月1日至5日各員工在不同時段、不同柜臺的銷售額。部分數據如圖,要求編寫程序,讀取該文件的數據,并統計每個員工的銷售總額、每個時段的銷售總額、每個柜臺的銷售總額。
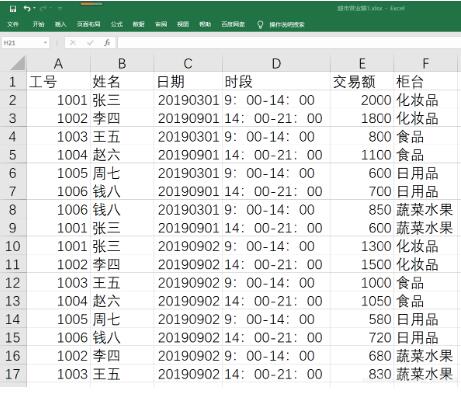
超市營業額1.xlsx文件圖
二、代碼展示:# -*- coding: utf-8 -*-'''' @Author : Jackma @Time : 2020/11/7 21:26 @File : 2020_11_7.py @Software: PyCharm @URL : www.jackmark.top @Version : '''# 1、查閱資料了解.docx文檔結構,然后編寫程序,輸出'test.docx'文檔正文中的所有紅色的文字。# 2、查閱資料了解.docx文檔結構,然后查閱資料,編寫程序,輸出'測試.docx'文檔中所有的超鏈接地址和文本。# 3、已知文件“超市營業額1.xlsx”中記錄了某超市2019年3月1日至5日各員工在不同時段、不同柜臺的銷售額。# 部分數據如圖,要求編寫程序,讀取該文件的數據,并統計每個員工的銷售總額、每個時段的銷售總額、每個# 柜臺的銷售總額。# 4、查閱資料,編寫程序操作Excel文件。已知當前文件夾中的文件“每個人的愛好.xlsx”的內容如圖中A到H列所# 示,要求追加一列,并如圖中方框所示進行匯總。 from docx import Documentfrom docx.shared import RGBColor from docx.opc.constants import RELATIONSHIP_TYPE as RTfrom openpyxl import load_workbook # 1def find_bold_red(): ’’’ 輸出文檔中的所有紅色的、加粗的文字 :return: ’’’ # 定義兩個列表 boldText = [] # 存儲加粗的文字 redText = [] # 存儲紅色字體的文字 name1 = input(’輸入你要查詢的文件名(without .docx):’) # doc1 = Document(’test.docx’) # 打開文檔 doc1 = Document(name1 + ’.docx’) # 打開文檔 for p in doc1.paragraphs: # 遍歷里面的每個段落 for r in p.runs: # 找每段中所有的run, run指連續的相同格式的字體 if r.bold: # 找到加粗字體 boldText.append(r.text) # 把run的文本放到boldText文本中 if r.font.color.rgb == RGBColor(255,0,0): # rgb(255,0,0)代表紅色,找到紅色字體 redText.append(r.text) result = {’red text’: redText, ’bold text’: boldText, ’both’: set(redText) & set(boldText) # 集合的交集 } # 輸出結果 for title in result.keys(): print(title.center(30, ’=’)) # 長度為30,center指居中,效果如下 # ===========red text============ for text in result[title]: print(text) find_bold_red() # 2# def find_Hyperlink():# ’’’# 只適用于WPS創建的文檔# 輸出'test.docx'文檔中所有的超鏈接地址和文本# :return:# ’’’# doc2 = Document(’test.docx’)# for p in doc2.paragraphs:# for index, run in enumerate(p.runs):# if run.style.name == ’Hyperlink’:# print(run.text, end =’:’)# for child in p.runs[index-2].element.getchildren():# text = child.text# if text and text.stratswith(’HYPERLINK’):# print(text[12:-2])## find_Hyperlink() def find_Hyperlink(): ’’’ 輸出'test.docx'文檔中所有的超鏈接地址和文本 :return: ’’’ docx_file=input(' 輸入你要查詢的文件名(without .docx): ') document = Document(docx_file + '.docx') rels = document.part.rels for rel in rels: if rels[rel].reltype == RT.HYPERLINK: # print('n 超鏈接文本為', rels[rel], ' 超鏈接網址為: ', rels[rel]._target) print(' 超鏈接網址為: ', rels[rel]._target) find_Hyperlink() # 3def money(): ’’’ 統計每個員工的銷售總額、每個時段的銷售總額、每個柜臺的銷售總額。 :return: ’’’ # 3個字典分別存儲按員工、按時段、按柜臺的銷售總額 persons = dict() periods = dict() goods = dict() ws = load_workbook(’超市營業額1.xlsx’).worksheets[0] for index, row in enumerate(ws.rows): # 跳過第一行的表頭 if index == 0: continue # 獲取每行的相關信息 _, name, _, time, num, good = map(lambda cell: cell.value, row) # 根據每行的值更新三個字典 persons[name] = persons.get(name, 0) + num periods[time] = periods.get(time, 0) + num goods[good] = goods.get(good, 0) + num print(persons) print(periods) print(goods) money()三、結果展示:
首先是測試文檔test.docx內容

圖1 test.docx文件圖
程序1、輸出'test.docx'文檔正文中的所有紅色的文字。

輸出'test.docx'文檔中所有的超鏈接地址和文本。
統計每個員工的銷售總額、每個時段的銷售總額、每個柜臺的銷售總額。

以上為個人經驗,希望能給大家一個參考,也希望大家多多支持好吧啦網。如有錯誤或未考慮完全的地方,望不吝賜教。
相關文章:

 網公網安備
網公網安備