python實(shí)現(xiàn)圖像識別的示例代碼
首先我們需要安裝PIL和pytesseract庫。PIL:(Python Imaging Library)是Python平臺上的圖像處理標(biāo)準(zhǔn)庫,功能非常強(qiáng)大。pytesseract:圖像識別庫。
我這里使用的是python3.6,PIL不支持python3所以使用如下命令
pip install pytesseractpip install pillow
如果是python2,則在命令行執(zhí)行如下命令:
pip install pytesseractpip install PIL
這時(shí)候我們?nèi)ミ\(yùn)行上面的代碼會發(fā)現(xiàn)如下錯(cuò)誤:

錯(cuò)誤提示的很明顯:No such file or directory :'tesseract'
這是因?yàn)槲覀儧]有安裝tesseract-ocr引擎
二、tesseract-ocr引擎光學(xué)字符識別(OCR,Optical Character Recognition)是指對文本資料進(jìn)行掃描,然后對圖像文件進(jìn)行分析處理,獲取文字及版面信息的過程。OCR技術(shù)非常專業(yè),一般多是印刷、打印行業(yè)的從業(yè)人員使用,可以快速的將紙質(zhì)資料轉(zhuǎn)換為電子資料。關(guān)于中文OCR,目前國內(nèi)水平較高的有清華文通、漢王、尚書,其產(chǎn)品各有千秋,價(jià)格不菲。國外OCR發(fā)展較早,像一些大公司,如IBM、微軟、HP等,即使沒有推出單獨(dú)的OCR產(chǎn)品,但是他們的研發(fā)團(tuán)隊(duì)早已掌握核心技術(shù),將OCR功能植入了自身的軟件系統(tǒng)。對于我們程序員來說,一般用不到那么高級的,主要在開發(fā)中能夠集成基本的OCR功能就可以了。這兩天我查找了很多免費(fèi)OCR軟件、類庫,特地整理一下,今天首先來談?wù)凾esseract,下一次將討論下Onenote 2010中的OCR API實(shí)現(xiàn)。可以在這里查看OCR技術(shù)的發(fā)展簡史。Tesseract的OCR引擎最先由HP實(shí)驗(yàn)室于1985年開始研發(fā),至1995年時(shí)已經(jīng)成為OCR業(yè)內(nèi)最準(zhǔn)確的三款識別引擎之一。然而,HP不久便決定放棄OCR業(yè)務(wù),Tesseract也從此塵封。數(shù)年以后,HP意識到,與其將Tesseract束之高閣,不如貢獻(xiàn)給開源軟件業(yè),讓其重?zé)ㄐ律?005年,Tesseract由美國內(nèi)華達(dá)州信息技術(shù)研究所獲得,并求諸于Google對Tesseract進(jìn)行改進(jìn)、消除Bug、優(yōu)化工作。
###安裝tesseract-ocr引擎
brew install tesseract
然后我們通過tesseract -v看一下是否安裝成成功
tesseract 3.05.01leptonica-1.75.0libjpeg 9b : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11
這時(shí)候我們運(yùn)行上面代碼會出現(xiàn)亂碼

這是因?yàn)閠esseract默認(rèn)只有語言包中沒有中文包,如下圖:
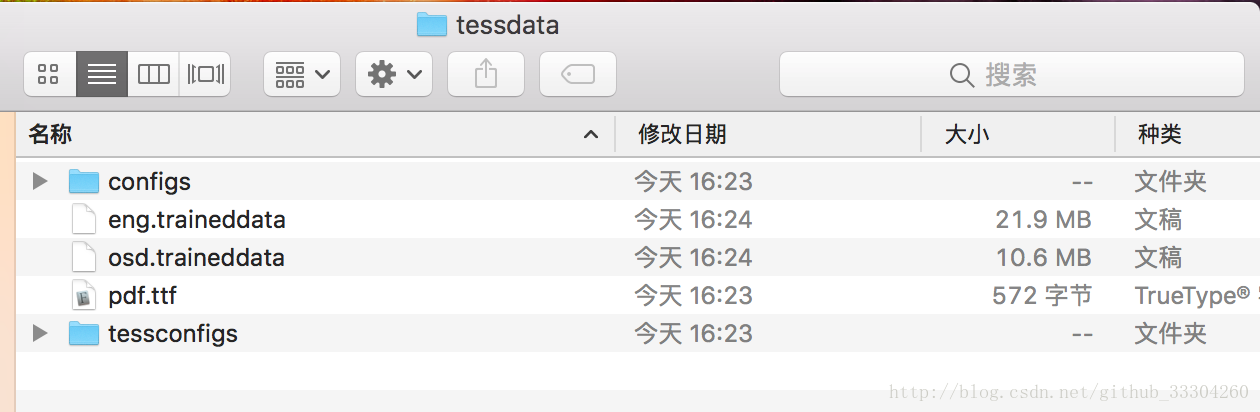
###安裝tesseract-ocr語言包我們?nèi)itHub下載我們需要的語言包,這里我只下載了chi_tra.traineddata和chi_sim.traineddatagithub:tesseract-ocr/tessdata然后放到/usr/local/Cellar/tesseract/3.05.01/share/tessdata路徑下面。
可以通過tesseract --list-langs查看本地語言包:

可以通過tesseract --help-psm 查看psm
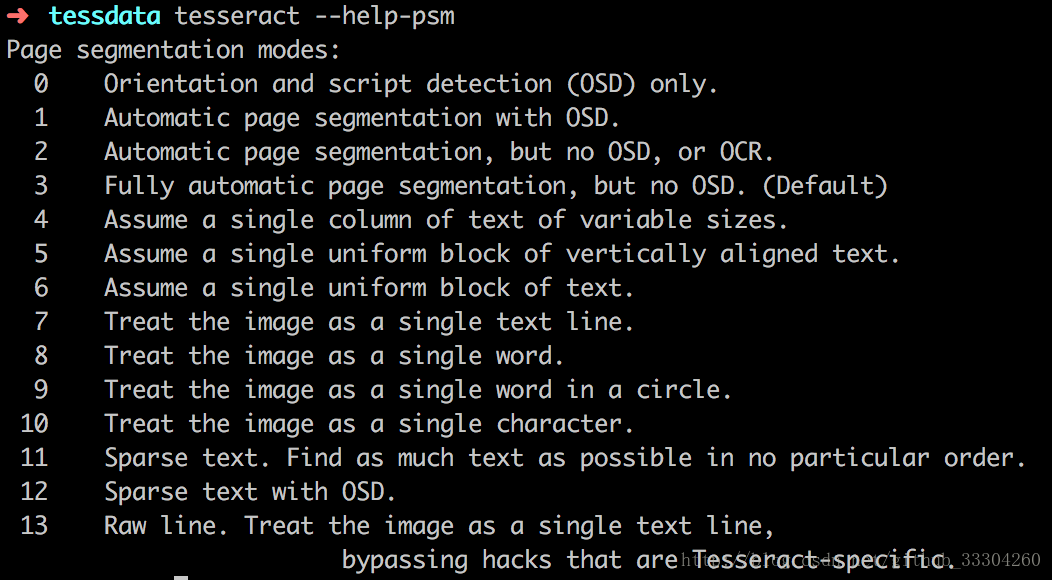
0:定向腳本監(jiān)測(OSD)1: 使用OSD自動分頁2 :自動分頁,但是不使用OSD或OCR(Optical Character Recognition,光學(xué)字符識別)3 :全自動分頁,但是沒有使用OSD(默認(rèn))4 :假設(shè)可變大小的一個(gè)文本列。5 :假設(shè)垂直對齊文本的單個(gè)統(tǒng)一塊。6 :假設(shè)一個(gè)統(tǒng)一的文本塊。7 :將圖像視為單個(gè)文本行。8 :將圖像視為單個(gè)詞。9 :將圖像視為圓中的單個(gè)詞。10 :將圖像視為單個(gè)字符。
為什么這里要強(qiáng)調(diào)語言包和psm,因?yàn)槲覀冊谑褂弥袝玫剑热缍鄠€(gè)語言包組合并且視為統(tǒng)一的文本塊將使用如下參數(shù):
pytesseract.image_to_string(image,lang='chi_sim+eng',config='-psm 6')
這里我們通過+來合并使用多個(gè)語言包。
接下來我們看一下配置好一切的正確結(jié)果。
import pytesseractfrom PIL import Imageimage = Image.open('../pic/c.png')code = pytesseract.image_to_string(image,lang='chi_sim',config='-psm 6')print(code)


此時(shí)大公告成。
到此這篇關(guān)于python實(shí)現(xiàn)圖像識別的示例代碼的文章就介紹到這了,更多相關(guān)python 圖像識別內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. PHP橋接模式Bridge Pattern的優(yōu)點(diǎn)與實(shí)現(xiàn)過程2. asp.net core項(xiàng)目授權(quán)流程詳解3. html中的form不提交(排除)某些input 原創(chuàng)4. js select支持手動輸入功能實(shí)現(xiàn)代碼5. CSS3中Transition屬性詳解以及示例分享6. bootstrap select2 動態(tài)從后臺Ajax動態(tài)獲取數(shù)據(jù)的代碼7. vue使用moment如何將時(shí)間戳轉(zhuǎn)為標(biāo)準(zhǔn)日期時(shí)間格式8. 開發(fā)效率翻倍的Web API使用技巧9. jsp文件下載功能實(shí)現(xiàn)代碼10. ASP常用日期格式化函數(shù) FormatDate()
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備